프로세스 = 부모자식 관계
부모 프로세스는 자식 프로세스를 생성하고 자식 프로세스는 또 다른 자식 프로세스 생성 가능
자식 프로세스는 할 일이 끝나면 부모 프로세스에 결과를 돌려주고 종료
자식 프로세스가 종료 되면 부모 프로세스로 리턴값을 돌려주고 종료된다.
프로세스 종류
데몬 프로세스
- 백그라운드 에서 특정 서비스 제공하기 위해 존재, 리눅스 커널에 의해 실행
고아 프로세스
- 자식 프로세스가 아직 실행중인데 부모가 없어지면 발생,
- (init)1번 프로세스가 고아 프로세스의 새로운 부모가 되도록 지원
좀비 프로세스
- 자식 프로세스가 실행을 종료했는데도 리턴값이 정상적으로 돌아오지 않았을 때, 프로세스 테이블 목록에 남아 있는 경우
- 좀비 프로세스가 증가하면,프로세스 테이블의 용량이 부족해서 일반 프로세스가 실행되지 않을 수도 있음.
프로세스 목록 보기
현재 실행 중인 프로세스의 목록을 보는 명령 : ps
| ps | ||
| 기능 | 현재 실행중인 프로세스 정보 출력 | |
| 형식 | ps 옵션 | |
| 옵션 | < 유닉스 옵션 > | -e : 시스템에서 실행중인 모든 프로세스의 정보 출력 -f : 프로세스에 대한 자세한 정보 출력 -u uid : 특정 사용자에 대한모든 프로세스 정보 출력 -p pid : pid로 지정한 특정 프로세스의 정보를 출력한다. |
| < BSD 옵션 > | a : 터미널에서 실행한 프로세스의 정보를 출력한다. u : 프로세스 소유자의 이름, CPU 사용량, 메모리 사용량 등 x : 시스템에서 실행중인 모든 프로세스 정보를 출력한다. |
|
| <GNU 옵션> | --pid PID 목록 : 목록으로 지정한 특정 PID 정보를 출력한다. | |
| 사용 예 | ps ps-ef ps aux |
|
ps -f
ps -f의 출력 정보
| 항목 | 의미 | 항목 | 의미 |
| UID | 프로세스를 실행한 사용자 ID | STME | 프로세스의 시작 날짜나 시간 |
| PID | 프로세스 번호 | TTY | 프로세스가 실행된 터미널의 종류와 번호 |
| PPID | 부모 프로세스 번호 | TIME | 시간정보 출력 |
| C | CPU 사용량(%값) | CMD | 실행되고 있는 프로그램 이름(명령) |
STAT에 사용되는 문자 의미
| 문자 | 의미 | 비고 | 문자 | 의미 | 비고 |
| R | 실행중(running) | STIME | 프로세스의 시작 날짜나 시간 | ||
| S | 인터럽트가 가능한 대기(sleep)상태 | s | 세션 리더 프로세스 | BSD 형식 |
|
| T | 작업 제어에 의해 정지된 (stooped)상태 | + | 포그라운드 프로세스 그룹 | ||
| Z | 좀비 프로세스(defunct) | l(소문자L) | 멀티 스레드 |
터미널에서 실행한 프로세스 정보 출력하기 : a
ps a
다양한 옵션 : a, u 옵션
a와 u옵션을 함께 사용하면, 터미널에서 실행한 프로세스의 상세정보를 출력, CPU와 메모리 사용량 등
ps au

| 항목 | 의미 | 항목 | 의미 |
| USER | 사용자 계정 이름 | VSZ | 사용하고 있는 가상 메모리의 크기 |
| $CPU | CPU 사용량을 퍼센트로 표시 | RSS | 사용하고 있는 물리적 메모리의 크기 |
| %MEM | 물리적 메모리 사용량을 퍼센트로 표시 | START | 프로세스 시작 시간 |
전체 프로세스 목록 출력하기 (BSD 옵션) :ax옵션
시스템에서 실행중인 모든 프로세스를 출력
-aux 옵션을 -ef처럼 시스템에서 실행 중인 모든 프로세스에 대한 자세한 정보를 출력
특정 사용자의 프로세스 목록 출력하기 : -u 옵션
- 더 상세한 정보를 보고 싶으면 -f옵션을 함께 사용( 옵션 사용 순서 지켜야 함 )
ps-ef 로 데이터를 가져오면 데이터 양이 많기 떄문에 grep 명령을 | 로 연결하여 특정 프로세스 에 대한 정보만 따로 가져와서 검색 하면 된다.
pgrep 명령을 이용해 특정 프로세스 정보 검색하기
| pgrep | |
| 기능 | 지정한 패턴과 일치하는 프로세스에 대한 정보를 출력한다 |
| 형식 | pgrep [옵션] [패턴] |
| 옵션 | -x : 패턴과 정확히 일치하는 프로세스 정보를 출력한다. -n : 패턴을 포함하고 있는 가장 최근의 프로세스 정보를 출력한다 -u 사용자 이름 : 특정 사용자에 대한 모든 프로세스를 출력한다. -l : PID와 프로세스 이름을 출력한다. -t term : 특정 단말기와 관련된 프로세스 정보를 출력한다. |
| 사용 예 | pgrep bash |
-bash 패턴을 지정하여 검색한 예

pgrep 명령에 -l ( 소문자 L ) 을 지정하여 PID에 이름만 출력함.
ps -fp $(pgrep -x bash)
ps에서 bash라는 이름을 가진 데이터를 추출하여 데이터를 표시한다.
옵션으로 사용자 명을 지정하여 검색을 가능함.
ps -fp $(pgrep -u user bash)
kill 명령을 이용해 프로세스 종료 가능.
| kill | |
| 기능 | 지정한 시그널을 프로세스에 보낸다 |
| 형식 | kill [ 시그널 ] PID |
| 시그널 | -2 : 이넡럽트 시그널을 보낸다. -9 : 프로세스를 갖에로 종료한다. -15: 프로세스가 관련된 파일을 정리하고 프로세스를 종료한다. 종료되지 않는 프로세스 |
| 사용 예 | kill 1001 kill -15 1001 kill -9 1001 |
ps -fp $(pgrep -x man) : man 이라는 패턴을 정확하게 인식하고있는 데이터를 ps로 리턴해라.
여기서 이 프로세스를 강제 종료 하려면,
kill -9 2688(프로세스 번호) 를 치면 된다.

pkill -x man
이라고 쳐도, 위의 kill 명령과정이 빠르게 진행된다, 그러나 이 명령어는 man이 포함되는 다른 프로세스가 있을 수도 있기 때문에, 다른 모든 man관련 프로그램도 종료가 된다.
프로세스 관리 도구
- top 명령 : 현재 실행중인 프로세스에 대한 정보를 주기적으로 출력
| 항목 | 의미 | 항목 | 의미 |
| PID | 프로세스 ID | SHR | 프로세스가 사용하는 공유 메모리 크기 |
| USER | 사용자 계정 | %CPU | CPU 사용량 |
| PR | 우선순위 | %MEM | 메모리 사용량(%) |
| NI | Nice 값 | TIME+ | CPU 누적 이용 시간 |
| VIRT | 프로세스가 사용하는 가상 메모리 크기 | COMMAND | 명령 이름 |
| RES | 프로세스가 사용하는 메모리 크기 |
| 항목 | 의미 | 항목 | 의미 |
| Enter, Space Bar | 화면을즉시 다시 출력한다. | u | 사용자에 따라 정렬하여 출력한다. |
| h, ? | 도움말 화면을 출력한다. | M | 사용하는 메모리 크기에 따라 정렬하여 출력한다. |
| k | 프로세스를 종료한다. 종료할 킬 프로세스의 PID를 물어본다. | p | CPU 사용량에 따라 정렬하여 출력한다. |
| n | 출력한 프로세스의 개수를 바꾼다 | q | top 명령을 종료한다. |
-t 옵션을 이용 하여 CPU 별로 사용량을 확인 가능
GNOME = 윈도우 작업 관리자 같은 형태로 출력할 수 있음
포 그라운드 작업
사용자가 입력한 명령이 실행되고 결과가 출력될 때까지 기다려야 하는 방식으로 처리되는 프로세스
sleep 100 ( 100초간 기다림)
백그라운드 작업
명령을실행하면 명령의 처리가 끝나는것과 관계없이 곧바로 프롬프트가 출력되어 사용자가 다른 작업을 계속할 수 있음
sleep 100&
프롬프트가 나와서 작업 진행 가능
백그라운드 작업과 출력 방향 전환하기
백그라운드로 처리할 때는 주로 출력과 오류 방향 전환을 하여 실행 결과와 오류 메세지 를 파일로 저장
작업 목록 보기 : jobs
| jobs | |
| 기능 | 백그라운드 작업을 모두 보여준다. 특정 작업 번호를 지정하면 해당 작업의 정보만 보여준다. |
| 형식 | jobs [ %작업번호 ] |
| % 작업 번호 | % 번호 : 해당 번호의 작업 정보를 출력한다. %+ 또는 %% : 작업 순서가 +인 작업 정보를 출력한다. %- : 작업 순서가 -인 작업 정보를 출력한다. |
| 사용 예 | jobs %1 j obs |

jobs 명령 출력 항목
| 항목 | 출력 예 | 의미 |
| 작업 번호 | [1] | 작업 번호로서 백그라운드로 실행할 때마다 순차적으로 증가한다([1], [2], [3], ...) |
| 작업 순서 | + | 작업 순서를 표시한다. + : 가장 최근에 접근한 작업 - : +작업보다 바로 전에 접근한 작업 공백 : 그 외의 작업 |
| 상태 | 실행 중 | 작업의 상태를 표시한다. 실행중(Running) : 현재 실행중 완료된(Done) : 작업이 정상적으로 종료된다 종료됨(Terminated) : 작업이 비정상적으로 종료된다. 정지(Stopped) : 작업이 잠시 중단된다. |
| 명령 | sleep 100& | 백그라운드로 실행중인 명령 |
작업전환하기.
| 명령 | 의미 |
| Ctrl + z 또는 stop [ % 작업 번호 ] | 포그라운드 작업을 중지한다.(종료하는것이 아니라 잠시 중단) |
| bg[%작업 번호] | 작업 번호가 지시하는 작업을 백그라운드 작업으로 전환한다. |
| fg [%작업 번호] | 작업 번호가 지시하는 작업을 포그라운드 작업으로 전환한다. |

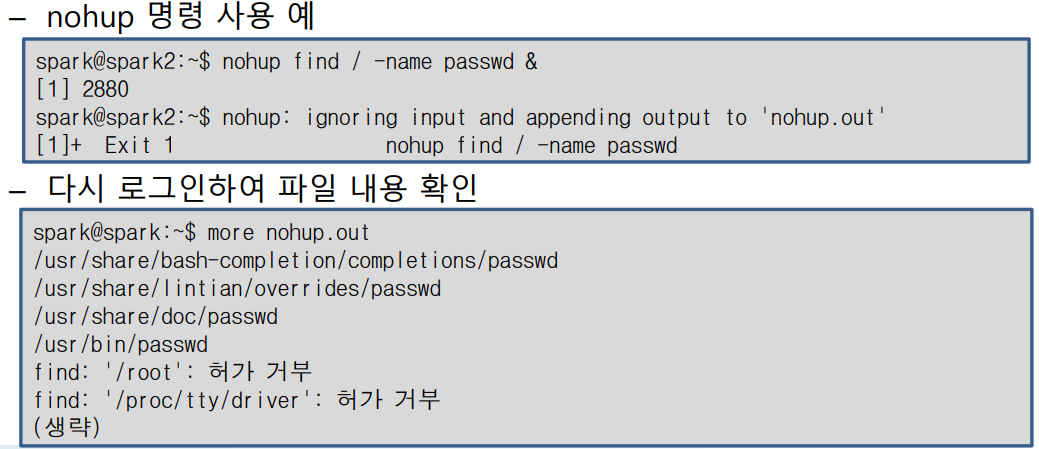
로그아웃 후에도 백그라운드 작업 계속 실행하기 : nohub
로그아웃 한 다음에도 작업이 완료될 때 까지 백그라우늗 작업 실행해야 할 경우 nohub 명령 사용
| nohub | |
| 기능 | 로그아웃 한 뒤에도 백그라운드 작업을 계속 실행한다. |
| 형식 | nohub 명령& |

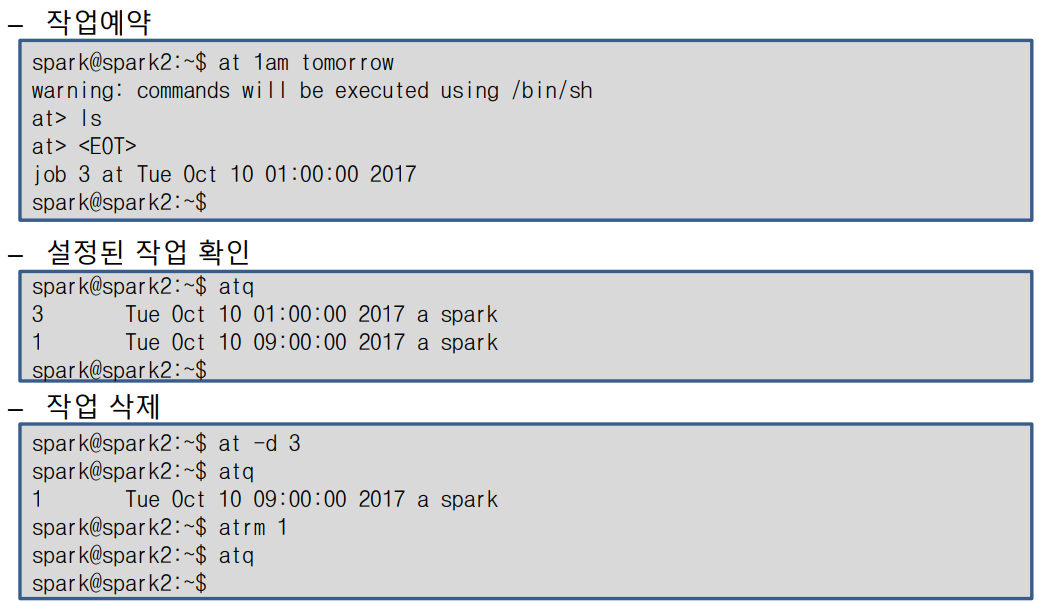
작업 예약
특정한 시간에 작업을 수행하도록 예약할 수 있는 두가지 방법이 있다.
정해진 시간에 한번만 수행
| at | |
| 기능 | 예약한 명령을 정해진 시간에 실행한다. |
| 형식 | at [ 옵션 ] 시간 |
| 옵션 | -l : 현재 실행 대기 중인 명령의 전체 목록을 출력한다.(atq 명령과 동일하다) -r 작업번호 : 현재 실행 대기 중인 명령에서 해당 작업 번호를 삭제한다(atrm과 동일) -m : 출력 결과가 없더라도 작업이 완료되면 사용자에게 메일로 알려준다. -f 파일 : 표준 입력 대신 실행할 명령을 파일로 지정한다. |
| 사용 예 | at -m 0730 tomorrow at 10:00 pm at 8:15 am May 30 |
at 명령 설치 방법 : sudo apt-get install at, sudo apt-get install mailutils
at명령을 사용하여 정해진 시간에 명령을 실행 예약 하려면, at명령 뒤에 시간을 명시하면 된다.

시간을 지정하는 방식
- at 4pm + 3 days : 지금부터 3일 후 오후 4시에 작업을 수행한다.
- at 10am Jul 31 : 7월 31일 오전 10시에 작업을 수행한다.
- at 1am tomorrow : 내일 오전 1시에 작업을 수행한다.
- at 10:00am today : 오늘 오전 10시에 작업을 수행한다.
이러한 at로 생성된 파일은 /var/spool/at 디렉터리에 저장된다.
root 사용자만 경로상의 파일을 확인이 가능하다.
at 작업 목록 확인하기 : -l 옵션, atq
at 명령으로 설정된 작업의 목록은 -l 옵션으로 확인이 가능하다.

atq 명령으로도 확인이 가능하다.

at 작업 삭제하기 : -d옵션, atrm
at명령으로 설정한 작업이 실행되기 전 삭제하려면 -d 옵션을 사용하고 삭제할 작업 번호를 지정한다.
at 명령 사용 제한하기.
관련 파일 : /etc/at.allow와 /etc/at.deny

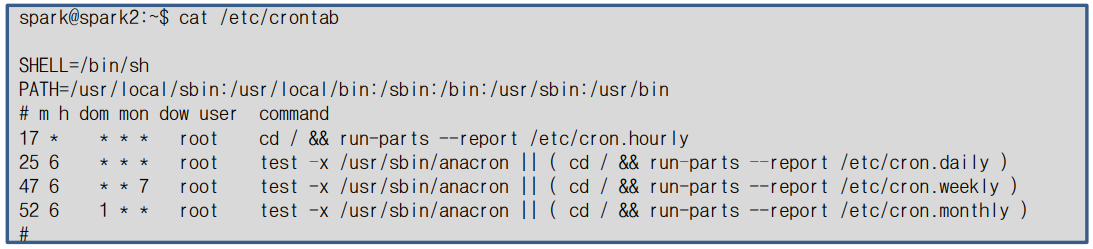
정해진 시간에 반복 수행
| crontab | |
| 기능 | 사용자의 crontab 파일을 관리한다. |
| 형식 | crontab [-u 사용자 ID] [옵션] [파일 이름] |
| 옵션 | -e : 사용자의 crontab 파일을 편집한다. -l : crontab 파일의 목록을 출력한다. -r : crontab 파일을 삭제한다. |
| 사용 예 | crontab -l crontab -u user1 -e crontab -r |
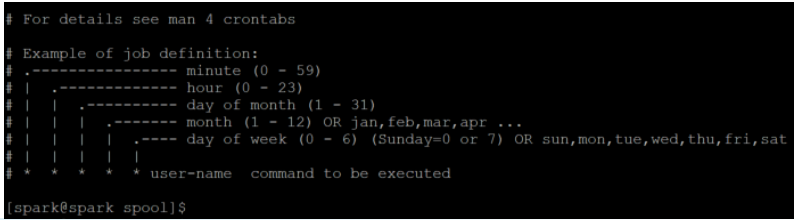
crontab 파일 생성하고 편집하기 : crontab -e
crontab 편집기는 기본적으로 VISUAL 또는 EDITOR 환경 변수에 지정된 편집기를 사용한다.

crontab -e 명령으로 편집한 파일을 저장하면 자동적으로 /var/spool/cron/crontabs 디렉터리에 사용자 이름으로 생성

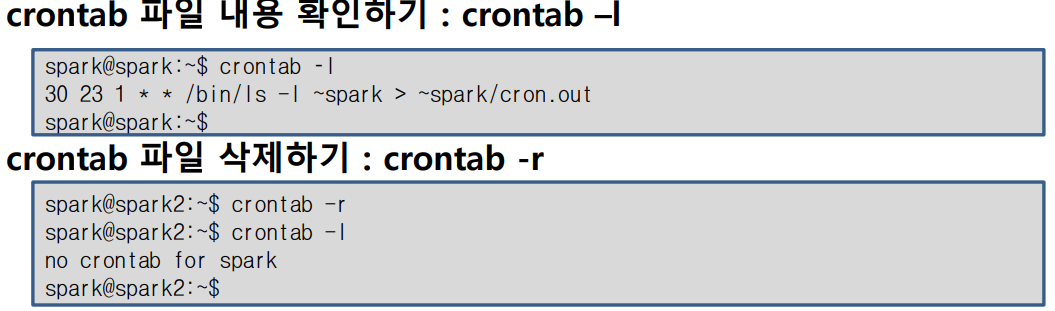
crontab 명령 사용 제한하기.
/etc/cron.allow, /etc/cron.deny 파일
cron.deny 파일은 기본적으로 있지만 cron.allow 파일은 관리자가 만들어야 함
두 파일이 적용되는 기준
- /etc/cron.allow 파일이 있으면 이 파일 안에 있는 사용자만 crontab 명령을 사용할 수 있다.
- /etc/cron.allow 파일이 없고 /etc/cron.deny 파일이 있으면 이 파일에 사용자 계정이 없어야 crontab 명령을 사용할 수 있다.
- /etc/cron.allow 파일과 /etc/cron.deny 파일이 모두 없다면 시스템 관리자만 crontab 명령을 사용할 수 있다.
두 파일이 모두 없는데 일반 사용자가 crontab 명령을 사용하려고 하면, 다음과 같은 메시지가 출력된다.

'대학교 코딩공부 > 운영체제 실습' 카테고리의 다른 글
| 운영체제 실습 11주차 리눅스 시스템, 데몬 프로세스 (0) | 2022.11.11 |
|---|---|
| 운영체제 실습 프로세스 ( fork, exc 함수 ) (0) | 2022.11.05 |
| 운영체제 실습 9주차 리눅스 마스터 2급 시험문제 풀이2020년6월13일 (0) | 2022.10.25 |
| 운영체제 실습 7주차 [ 파일 접근 권한 관리 ] (0) | 2022.10.12 |
| 운영체제 실습 6주차 [ 쉘 의 기능 ] (0) | 2022.10.05 |