






728x90
우분투 패키지의 개요
리눅스에서 주로 사용하는 패키지
- deb: 데비안, 우분투 계열에서 사용하는 패키지
- RPM(Redhat Package Manager): 레드햇에서 만든 패키지 관리 도구
우분투 패키지의 특징
- 바이너리 파일로 되어 있어 컴파일이 필요 없다.
- 패키지의 파일들이 관련 디렉터리로 바로 설치된다.
- 한번에 설치된 패키지의 파일을 일괄적으로 삭제할 수 있다.
- 기존에 설치된 패키지를 삭제하지 않고 바로 업그레이드 할 수 있다.
- 패키지의 설치 상태를 검증할 수 있다.
- 패키지에 대한 정보를 제공한다.
- 해당 패키지와 의존성을 가지고 있는 패키지가 무엇인지 알려준다.
- 의존성이 있는 패키지를 미리 설치할 수도 있고, apt-get 명령을 사용하면 의존성이 있는 패키지가 자동으로 설치된다.
우분투 패키지의 카테고리
공식적으로 데비안 배포판에 포함된 모든 패키지는 데비안 자유 소프트웨어 지침에 따라 자유롭게 사용하고 배포할 수 있음
우분투도 네 개의 카테고리로 나누어 소프트웨어를 제공한다.
- main : 우분투에 의해 공식적으로 지원되며 자유롭게 배포 가능
- restricted : 우분투에 의해 지원되나 완전한 자유 라이선스 소프트웨어는 아니다.
- universe : 리눅스에서 사용할 수 있는 거의 대부분의 소프트웨어로 자유 소프트웨어일 수 도 있고 아닐 수도 있으며, 기술적 지원을 보장하지 않음.
- multiverse : 자유 소프트웨어가 아닌 소프트웨어가 포함되어 있으며, 개인이 직접 라이선스를 확인해야 한다.
우분투 패키지 저장소
- 우분투는 패키지와 패키지에 대한 정보를 저장하고 있는 서버인 패키지 저장소 라는 개념을 사용한다.
- 패키지 저장소에서는 패키지의 기능 추가나 보안 패치 등 지속적인 업그레이드를 집중적으로 관리한다.
- 사용자는 저장소에 접속하여 최신 패키지를 다운받아 설치 가능하다.
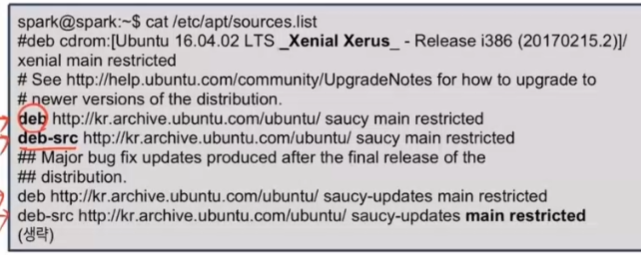
- 패키지 저장소에 대한 정보는 /etcc/apt/sources.list 파일에 저장된다.
- 패키지유형 ; deb 는 바이러니 패키지의 저장소를, deb-src는 패키지의 소스 저장소를 의미한다. 보통 한 저장소에 바이너리와 소스를 함께 저장한다.
- 저장소 주소 : http프로토콜을 사용하는 URL주소를 사용한다.
- 우분투 버전 정보 : 저장소에서 관리하는 패키지에 해당하는 우분투의 버전을 표시한다. 버전은 번호가 아니라 버전의 이름을 사용한다.
- 카테고리 : 저장소가 가지고 있는 소프트웨어 카테고리 를 표시한다.
우분투 패키지 설치
APT 명령으로 패키지 설치
apt-cache 명령 : APT 캐시 에서 정보를 검색하여 출력한다.
| apt-cache | |
| 기능 | APT 캐시에 질의하여 여러가지 정보를 검색한다. |
| 형식 | apt-cache [옵션] 서브 명령 |
| 옵션 | -f : 검색 결과로 패키지에 대한 전체 기록을 출력한다. -h : 간단한 도움말을 출력한다. |
| 서브 명령 | stats : 캐시의 통계 정보를 출력한다. dump : 현재 설치되어 있는 패키지를 업그레이드 한다. search 키워드 : 캐시에서 키워드를 검색한다. showpkg 패키지명 : 패키지의 의존성 정보와 역의존성 정보를 검색하여 출력한다. show 패키지명 : 패키지의 간단한 정보를 출력한다. pkgnames : 사용 가능한 모든 패키지의 이름을 출력한다. |
| 사용 예 | apt-cahce stats pat-cache show vsftpd apt-cache search vsftpd |
apt-cache 명령
- APT 캐시 통계 정보 보기 : stats
- 전체 패키지 이름 : 패키지 이름의 전체 개수
- 일반 패키지 : 일반적으로 사용하는 패키지의 개수
- 순수 가상 패키지
- 가상 패키지는 패키지의 이름만 제공하며 그 일므을 가진 별도의 패키지가 실제로 있는 것은 아니다.
- 단일 가상 패키지
- 한 패키지가 특정 가상 패키지의 기능을 제공한다.
- 혼합 가상 패키지
- 특정 가상 패키지를 제공하거나 가상 패키지의 이름을 패키지 이름으로 사용하는 경우
- 빠짐 : 의존성은 있지만 어떠한 패키지도 제공하지 않는 패키지
- 개별 버전 전체 : 캐시에 있는 패키지 버전의 개수를 의미

apt-cache 명령
사용 가능한 패키지 이름 보기 : pkgnames | grep mysql

패키지 이름 검색하기 : search

패키지 정보 검색하기 : show
- 버전, 패키지 크기, 카테고리, 채크섬 등 패키지에 관한 정보를 확인하려면 show 서브 명령을 사용한다.

apt-get 명령
| apt-get | |
| 기능 | 패키지를 관리한다. |
| 형식 | apt-get [옵션] 서브명령 |
| 옵션 | -d : 패키지를 내려받기만 한다. -f : 의존성이 깨진 패키지를 수정하려고 시도한다. -h : 간단한 도움말을 출력한다. |
| 서브 명령 | update : 패키지 저장소에서 새로운 패키지 정보를 가져온다. ipgrade : 현재 설치되어 있는 패키지를 업그레이드 한다. install 패키지명 : 패키지를 설치한다 remove 패키지명 : 패키지를 삭제한다 download 패키지명 : 패키지를 현재 디렉터리에 내려받는다. autoclean : 불완전하게 내려받았거나 오래된 패키지를 삭제한다 clean : /var/cache/apt/crchives에 캐시되어 있는 모든 패키지를 삭제하여 디스크를 확보한다 check : 의존성이 깨진 패키지를 확인한다. |
| 사용 예 | apt-get update apt-get install vsftpd |
패키지 정보 업데이트하기 : update
- /etc/apt/sources.list에 명시한 저장소에서 패키지 정보를 읽어 동기화.
- 새로운 패키지 정보를 가져와서 APT 캐시를 수정
- 사용 가능한 패키지들과 그 버전들의 리스트를 업데이트
- 최신 버전 패키지가 있는 지를 확인하고 우분투에 알려준다.

패키지 업그레이드 하기 : upgrade
- 현재 설치되어 있는 모든 패키지 중에서 새로운 버전이 있는 패키지를 모두 업그레이드
- 우분투에 있는 패키지들을 실제로 최신버전으로 업그레이드

특정 패키지 설치 또는 업그레이드 하기 : install
- 하나 이상의 패키지를 설치하거나 업그레이드 할 떄는 install 서브 명령을 사용한다.

- 여러 패키지를 한번에 설치하려면 다음과 같이 패키지 이름을 나열

- 패키지를 설치할 떄 업그레이드를 하지 않으려면 -no-upgrade 옵션을 사용

- 새로운 패키지를 설치하지 않고 업그레이드만 할 떄는 --only-upgrade 옵션을 사용

패키지 삭제하기 : remove

- 설정 파일을 포함하여 패키지를 삭제하려면 purge 서브 명령을 사용한다.

패키지 자동 정리 및 삭제하기 : autoremove
- 자동으로 설치되었으나 필요 없는 패키지는 autoremove 서브 명령으로 정리한다.

디스크 공간 정리하기 : clean
- 검색했거나 내려받은 패키지 파일들을 삭제하고 디스크 공간을 정리한다.

패키지 내려받기 : download
- 패키지를 설치하지 않고 내려받기만 하려면 download 서브 명령을 사용

패키지의 소스 관련 서브 명령 : source
- 특정 패키지의 소스코드를 내려받기만 하는 경우

- 특정 패키지의 소스코드를 내려받고 압축을 푸는 경우

dpkg 명령으로 패키지 관리하기
| dpkg | |
| 기능 | 데비안의 패키지 관리 명령이다. |
| 형식 | dpkg [옵션] 파일명 또는 패키지명 |
| 옵션 | -l : 설치된 패키지의 목록을 출력한다. -l 패키지명 : 패키지의 설치 상태를 출력한다. -s 패키지명 : 패키지의 살세 정보를 출력한다. -s 패키지명 : 패키지의 상세 정보를 출력한다. -S 경로명 : 경로명이 포함된 패키지를 검색한다. -L 패키지명 : 패키지가 설치된 파일의 목록을 출력한다. -c .deb 파일명 : 지정한 .deb 파일의 내용을 출력한다. -i .deb 파일 : 해당 파일을 설치한다(sudo). -r 패키지명 : 해당 패키지를 삭제한다(sudo) -P 패키지명 : 해당 패키지와 설정 정보를 모두 삭제한다(sudo). -x .deb 파일 디렉터리 : 해당 파일을 지정한 디렉터리에 풀어놓는다. |
| 사용 예 | dpkg -l dpkg -s netcat dpkg -S /bin/ls sudo dpkg -i netcat_1.10-40_all.deb |
패키지 목록 보기 -l 옵션
- 출력 결과에서 첫 글자는 상단의 희망 상태를 나타내고, 두번째 글자는 상태를 표시한다.

aptitude 명령으로 패키지 관리하기
- aptitude는 APT 명령처럼 패키지 관리를 자동화하여 쉽게 작업할 수 있도록 해줌
- 옵션이나 서브명령 없이 실행할 경우 curses를 이용한 비주얼 모드로 동작한다.
| aptitude | |
| 기능 | 우분투에서 패키지를 관리한다. |
| 형식 | aptitude [ 서브명령 ] |
| 서브 명령 | 단독 실행 : curses 프로그램이 나타난다. search 키워드 : 키워드를 검색하여 일치하는 패키지의 목록을 출력한다. update : 패키지 저장소를 업데이트 한다. upgrade : 모든 패키지를 최신 버전으로 업그레이드 한다. show 패키지명 : 패키지에 대한 자세한 정보를 보여준다. download 패키지명 : 패키지를 내려받는다. clean : 패키지 캐시 디렉터리에서 모든 패키지 파일을 삭제한다. install : 패키지를 설치한다. remove : 패키지를 삭제한다. purge : 패키지와 설정 파일을 모두 삭제한다. |

Elasticsearch 설치 및 패키지 관리하기
- Elasitcsearch 의 최신 저장소 목록 확인 업데이트
- Sudo 명령어로 설치 및 apt-get 확인
- sudo dpkg -s elasticsearch
파일 아카이브와 압축
파일 아카이브
파일을 묶어서 하나로 만든 것
tar(tape archive) 명령은 원래 여러 파일이나 디렉터리를 묶어서 마그네틱 테이브퐈 같은 이동식 저장 장치에 보관하기 위해 사용하는 명령
현재는 다른 시스템과 파일을 주고받거나, 백업을 하기 위해 여러 파일이나 디렉터리를 하나의 아카이브 파일로 생성하거나, 기존 아카이브에서 파일을 추출하기 위해 사용한다.
| tar | |
| 기능 | 파일과 디렉터리를 묶어 하나의 아카이브 파일을 생성한다. |
| 형식 | tar 명령[옵션] [ 아카이브 파일 ] 파일 이름 |
| 명령 | c : 새로운 tar 파일을 생성한다. t : tar 파일의 내용을 출력한다. x : tar 파일에서 원본 파일을 추출한다. r : 새로운 파일을 추가한다. u : 수정된 파일을 업데이트 한다. |
| 옵션 | f : 아카이브 파일이나 테이프 장치를 지정한다. 파일 이름을 - 로 지정하면 tar 파일 대신 표준 입력에서 읽어들인다. v : 처리하고 있는 파일의 정보를 출력한다. h : 심벌릭 링크의 원본 파일을 포함한다. p : 파일 복구 시 원래의 접근 권한을 유지한다. j : bzip2로 압축하거나 해제한다. z : gzip로 압축하거나 해제한다. |
| 사용 예 | tar cvf unix.tar Unix tar xvf unix.tar |
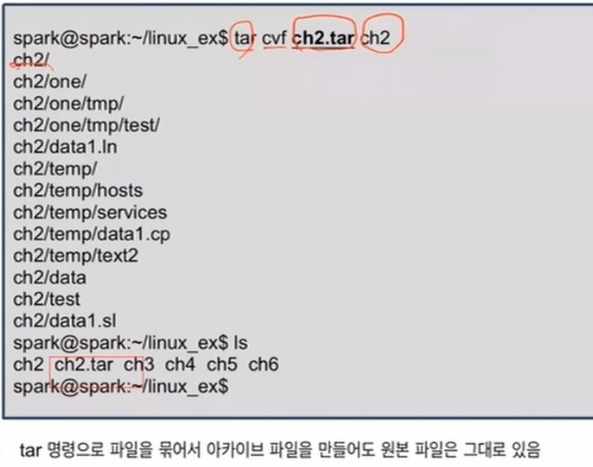
아카이브 생성하기 : cvf
아카이브 풀기 : xvf

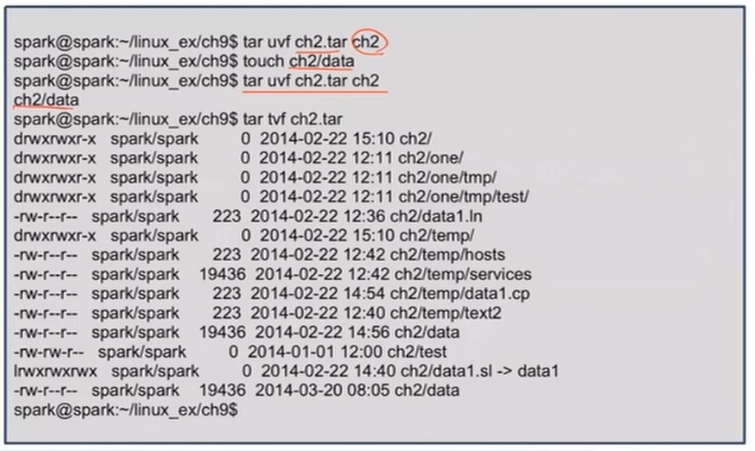
아카이브 업데이트 하기 : uvf
- u기능은 지정한 파일이 아카이브에 없는 파일이거나, 아카이브에 있는 파일이지만, 수정된 파일일 경우 아카이브의 마지막에 추가한다.
- ch2/data 파일의 수정 시간을 touch 명령으로 수정 후 아카이브 업데이트
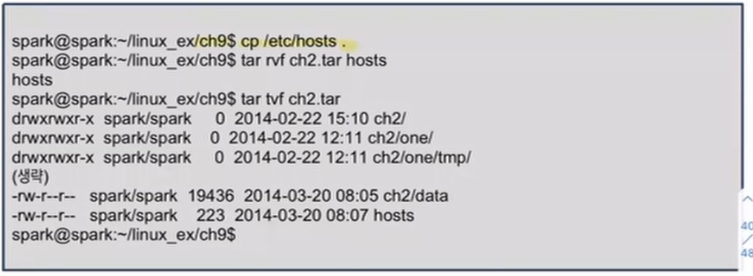
아카이브에 파일 추가하기 : rvf
- r 기능은 지정한 파일을 무조건 아카이브의 마지막에 추가한다.
파일 압축과 아카이브
- 아카이브를 생성하면서 동시에 압축 수행
- 예 : gzip으로 압축

- 예 bzip2 로 압축 실행 bzip2로 압축할 경우 j 옵션을 사용한다.

- 압축한 아카이브 파일의 내용은 tvf로 확인이 가능하며, xvf로 추출이 가능하다.

파일 압축하기 : gzip/gunzip - .gz 파일
| gzip | |
| 기능 | 파일을 압축한다. |
| 형식 | gzip [ 옵션 ] 파일 이름 |
| 옵션 | -d : 파일 압축을 해제한다. -l : 압축된 파일의 정보를 보여준다. -r : 하위 디렉터리를 이동하여 파일을 압축한다. -t : 압축 파일을 검사한다. -v : 압축 정보를 화면에 출력한다. -9 : 최대한 압축한다. |
| 사용 예 | gzip a.txt gzip -v b.txt c.txt |

압축 파일의 내용 보기 : zcat
| zcat | |
| 기능 | gz로 압축된 파일의 내용을 출력한다. |
| 형식 | zcat 파일 이름 |
| 사용 예 | zcat abc.gz zcat abc |

압축 풀기 : gunzip
| gunzip | |
| 기능 | gz로 압축된 파일의 압축을 푼다. |
| 형식 | gunzip 파일 이름 |
| 사용 예 | gunzip abc.gz gunzip abc |

bzip2/bunzip2 : .bz2 파일
| bzip2 | |
| 기능 | 파일을 압축한다. |
| 형식 | bzip2 [ 옵션 ] 파일 이름 |
| 옵션 | -d : 파일 압축을 해제한다. -l : 압축된 파일의 내용을 보여준다. -t : 압축 파일을 검사한다. -v : 압축 정보를 화면에 출력한다. --best : 최대한 압축한다. |
| 사용 예 | bzip2 abc.txt bizp2 -v a.txt b.txt |


728x90
'대학교 코딩공부 > 운영체제 실습' 카테고리의 다른 글
| 14주차 리눅스 네트워크 (0) | 2022.12.04 |
|---|---|
| 운영체제실습 기말고사 준비 (0) | 2022.12.01 |
| 12주차 파일시스템과 디스크관리 (0) | 2022.11.17 |
| 운영체제 실습 11주차 리눅스 시스템, 데몬 프로세스 (0) | 2022.11.11 |
| 운영체제 실습 프로세스 ( fork, exc 함수 ) (0) | 2022.11.05 |


















