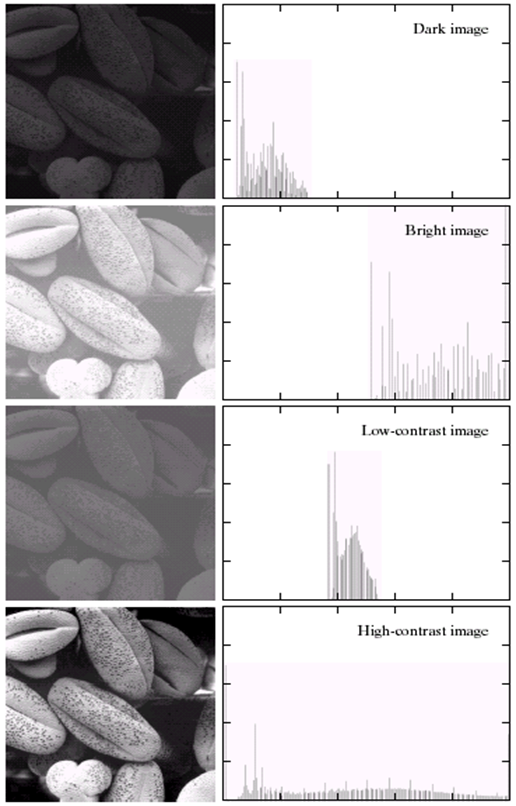
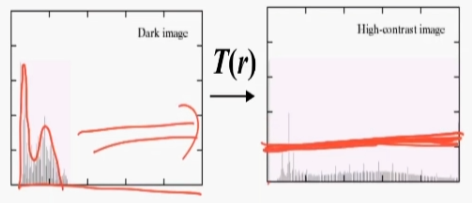
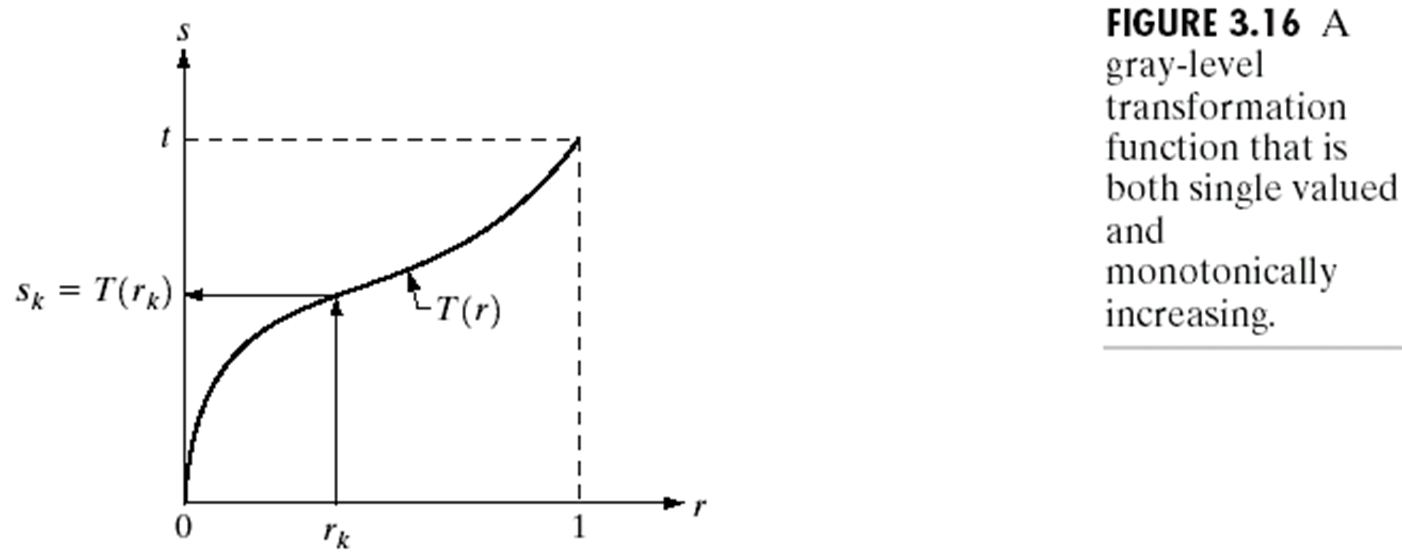
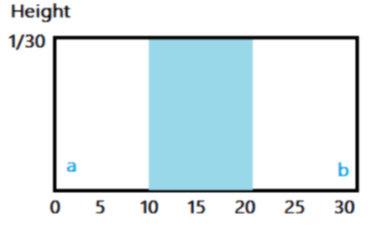
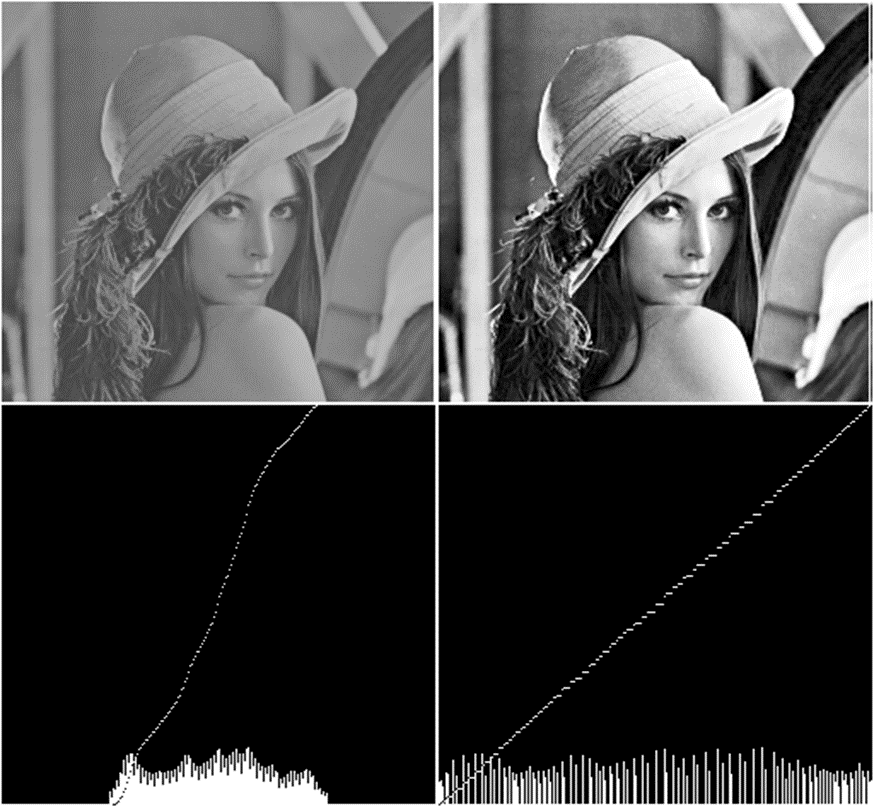
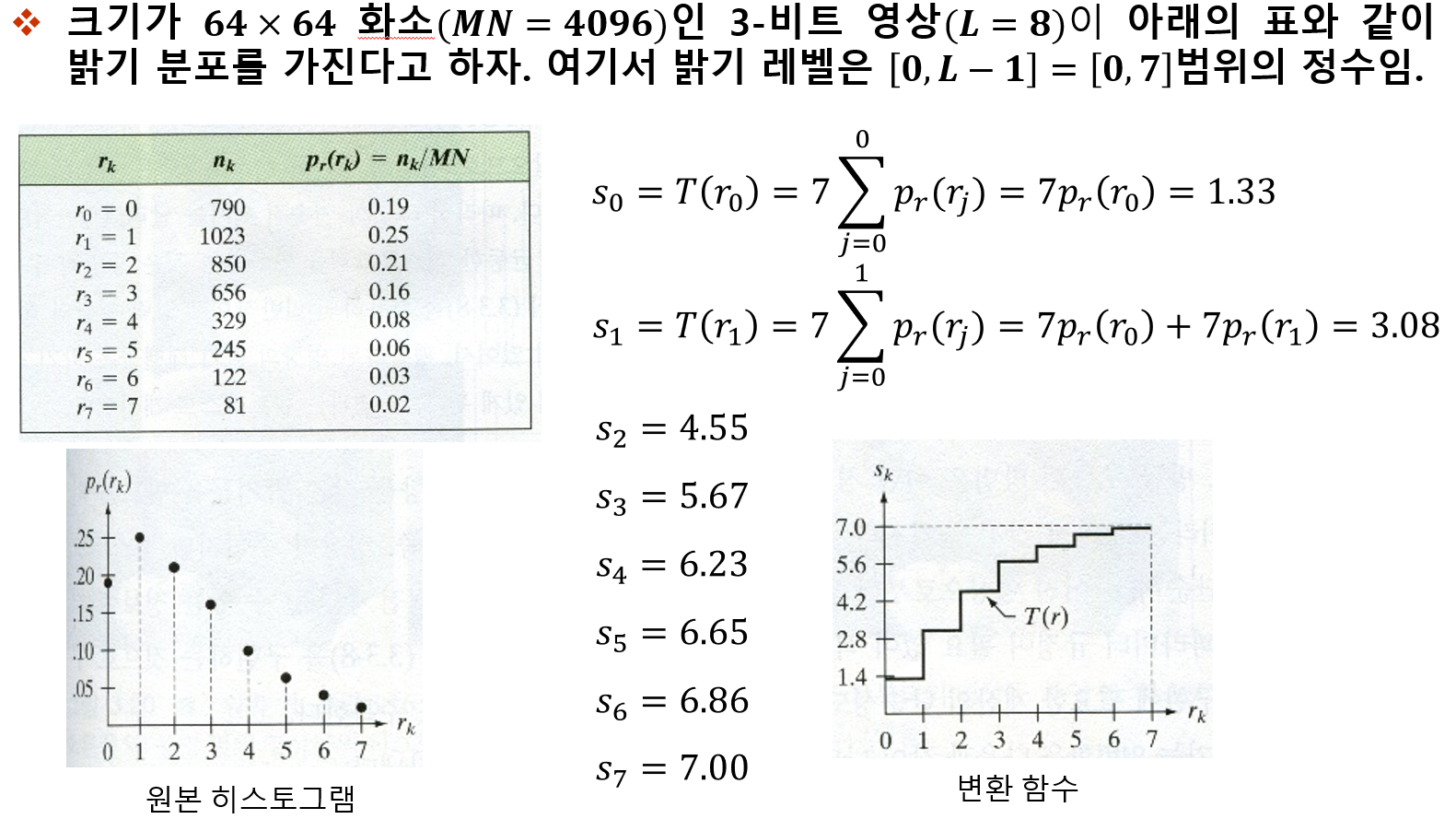
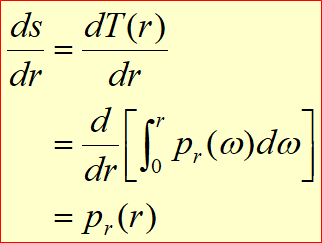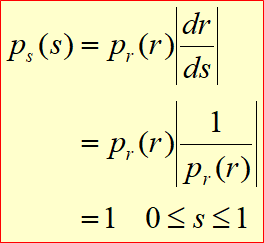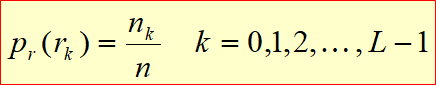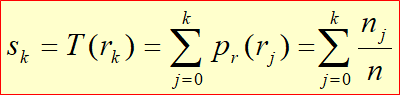히스토그램 평탄화 대비를 강화하는 기법중 가장 많이 사용하는 기법 Histogram h(rk)=nkrk = k번째 gray level 값이다. 그레이 픽셀 값이다. nk = 픽셀 계수. rk 에 h라는 값을 통과시키면 나오는 값. 4 4 3 3 4 4 3 3 4 1 2 3 0 1 2 3 input image r이 0인경우 1개 r이 1인경우 1이 2개 r이 2인경우 2개 r이 3인경우 6개 등 픽셀값이 n인 값이 몃개 있느냐 에 따라 gray level이 정해진다. 일반적으로 히스토그램은 막대 그레프로 많이 그리게 된다. Normalized Histogram 정규화된 히스토그렘 = 확률 개념과 같다. $p(r_{k}) \equiv \frac{n_{k}}{..
리눅스 문서편집기 GUI 환경인 그놈에서 제겅화는 gedit 유닉스에서부터 사용했던 행 편집기와 화면 편집기 구분 종류 행 단위 편집기 ed, ex, sed 화면 단위 편집기 vi, emacs GUI 편집기 gedit 행 단위 편집기 ed : 유닉스 초기 편집기 잘 안쓴다 ex : 행 편집이지만 vi에 연결하여 vi의 확장자형태로 사용 sed : 스트림 편집기로 일반적 편집기와 다르게 지시명령에 따라 파일의 내용을 일괄적으로 바꿔서 출력해준다. 화면단위 편집기 vi : 리눅스에서 일반적으로 사용할 수 있는 화면 편집기 emacs : 제공하는 기능이 매우 다양하지만, 사용법이 어렵고 복잡하여 전문가가 사용 모드형과 비모드형 편집기 모드형 입력모드, 명령모드 구분 입력모드 = 텍스트 입력 , 명령모드 = 텍..
웹 크롤링 웹 크롤링 (Crawling) 또는 웹 스크랩핑 (Scraping)은 웹 페이지를 원본 그대로 불러와 웹 페이지 내에 데이터를 추출하는 기술 크롤링(Crawling)은 사전적으로 ' 기어다니는것 ' 을 뜻하기도 한다. 웹 크롤링을 하기 위해 웹 소캣을 이용하여 원하는 웹사이트 연결 요청을 진행해야 한다. 연결 요청을 응답으로 웹 서버는 응답을 보내면 보통 HTML이나 JSON으로 변환한다. 파이썬 데이터 크롤링
데이터의 발전 빅데이터 시대가 되면서 수치 중심의 데이터 -> 대량의 텍스트, 이미지 음성 모든 산업분야 데이터 처리 가능해짐 정형데이터, 반정형데이터, 비정형데이터 3가지가 있다. 정형데이터 미리 정해진 형식으로 구조화된 데이터 엑셀시트, RDBMS테이블 등 반정형 데이터 특정한 형식에 따라 저장된 데이터 이지만, 정형데이터와 달리 형식에 대한 설명을 함께 제공해야 한다. XML, JSON 등 비정형 데이터 정해진 구조가 없이 저장된 데이터. 빅데이터 대부분을 차지하는 텍스트, 영상, 이미지 등이 대표적인 사례 데이터의 종류 미디어 클라우드 웹 사물인터넷 데이터베이스 오픈데이터/API 데이터 확장자 종류 CSV파일, EXCEL파일, JSON파일 CSV 각 라인의 컬럼이 콤마로 분리된 텍스트 데이터 가장..