
YARN = 33P 의 4자기 노드의 동작
방식 이해하기
(1) client가 RM에게 작업을 요청함
(2) RM은 AM을 구동함
(3) AM은 application 견적 보고 필요한 리소스를 요청함
(4) NM을 통해 application용 컨테이너를 구동함 (map task, reduce task, spark executor 등)
(5) 컨테이너 내에서 task를 수행함
Client에서 작업이 들어온다 -> Name노드에서 명령을 받고 스케줄러를 받아와서 데이터를 어찌 분할할지 결정 그 후 지정할 Data Node에 있는 Application Master에 작업명령을 할당. 그 이유는 효율성 때문에 이런 분할방식을 사용함.
그 후 Data Node 의 Application Master 가 더 많은 자원을 필요로 하면 Name Node의 Scheduler에게 요청한다.
그 이후 Application Master가 Scheduler와 협상이 끝나면 Node Manager에게 작업을 명령하고 Container에 실행를 명령한다.
Application 마스터에게 나머지 node가 데이터완료 작업결과를 보내고 Application가 각 Node Manager에게 작업 완료및 추가사항을 전달하고 Node의 상태를 name Node에게 말하고 사용이 완료된 자원을 반납한다.
삼각 피라미드 형태로 작업방식이 구상된다.
Name Node = 작업 명령을 시키는곳
Data Node = 작업 데이터가 물리적으로 존재하는 곳
Resource Manager = 자원관리자
Application Manager = 작업의 분할을 해주는 역활
Scheduler = 어플리케이션 매니저의 비서같은 역활 , 작업완료 목표 날짜를 정해놓고 조정함
Node Manager = Data Node의 최종명령권자
Data Node 의 Application Master = DataNode의 자원할당을 관리함
Container = 자원
HDFS = 10P 의 Linux 데이터 구동방식 이해
HDFS = 11P 의 Namenode와 Datanode를 확인하기
namenode = 마스터이고 Datanode를 컨트롤 하게 된다.
Datanode = 데이터를 보관하고있는 node.각자 다른 명령을 수행한다.그러나 데이터는 같다. 하나가 손상되어도 다 같은 데이터를 가지고 있어서 다른걸 복사 붙여넣기 하면 된다.
하둡을 설치하면 버추얼 호스트는 4개 설치하면 된다.
Datanode는 Namenode의 Bblock1과 Block2의 데이터노드를 하나씩 복사해서 가지고 있다.
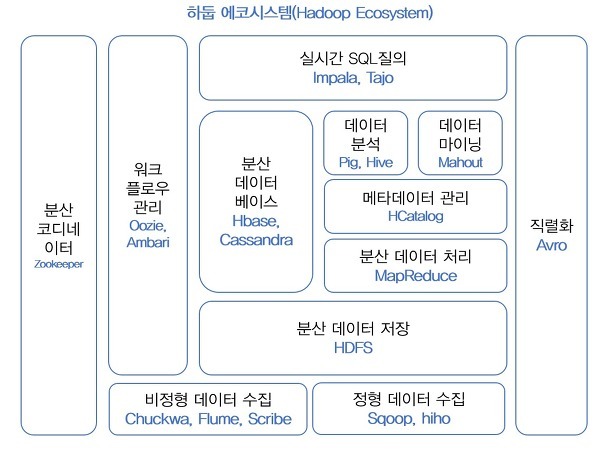
하둡 에코 시스템 RPC = 데이터 직렬화 P13
Core = 파일시스템과 I/O, 추상화 API RPC/Persistence
데이터 직렬을 하는데 Cross - language serialization이 가능하다 14P
Mapreduce - Distributed execution 을 하는데 fault- tolerance [ 오류 저항력 ] 을 한다.15p
Avro = 아파치에서 만든 프레임웤,
원격 프로시저 호출, 데이터 직렬화 기능 제공
언어 중립적인 데이터 직렬화 시스템. JSON과 비슷한 형식이나 스키마가 존재한다.
MapReduce = 여러 노드에 태스크를 분배하는방법
맵과 리듀스의 두단계로 구성됨.
ex) 엄청난 양의 텍스트를 계산해야할 때 텍스트를 분할하고 분할된 텍스트를 단어별로 자른다음 단어의 중복 횟수를 확인.한다. 이렇게 각 노드별로 단어의 중복횟수가 나오고. 그 중복횟수를 다 합하여 결과로 출력한다.
여기서 분할된 단어데이터를 분할하고 연산하는걸 Map, 각 블럭의 결과를 합하는걸 Reduce 라고 한다.
HDFS = 구글파일시스템에서 왔는데, 분산환경에서 데이터를다루기 위해 사용.
대용량 데이터를 범용 서버로 처리 가능.
용량 확장이 용이함
높은 처리량 실현 가능
슬레이브 노드 일부가 고장나도 데이터 손실 방지 가능
ZooKeeper = Coordination service를 하겠다. configuration을 하는 역활
하둡의 다른 프로그램이 동물 이름에서 따온게 많다. 그래서 그 프로그램들을 종합적으로 관리하는게 주키퍼
HBase = 스토리지로 분산환경에서의 데이터를 다루게 되는데, 구조화된 대용량의 데이터에 빠른 임의접근을 제공.
구글의 빅 테이블과 비슷한 데이터 모델을 가짐
HDFS의 데이터에 대한 실시간 임의 읽기/쓰기 기능을 제공
Pig = Data flow language를하겠다
대용량 데이터셋을 좀 더 고차원적으로 처리할 수 있도록 한다.
다중값과 중첩된 형태를 보이는 좀 더 다양한 데이터 구조를 지원한다.
Hive = Data에 대한 query execution을 하곘다
Chukwa = 22P ~ 데이터들의 전송을 원활하게 해주는 시스템
Hive
데이터를 모델링하고 프로세싱 하는 경우 많이 사용하는 데이터 웨어하우징용 솔루션
HDFS에 저장된 데이터의 구조를 정의하는 방법을 제공, 데이터를 대상으로 SQL과 유사한 HiveQL쿼리를 이용하여 데이터 조회방법 제공
맵 리듀스의 모든 기능 제공
Chukwa
분산된 서버에서 로그 데이터를 수집하여 저장하며, 저장한 데이터를 분석하기 위해 만들어짐
하둡 클러스터 로그, 서버 상태정보 등을 관리함
키워드 기준으로 각각 2~3줄씩은 써줄수 있을정도로 알고있자
하둡 분산 파일 시스템이 나온 이유.
빅 데이터( 단일 컴퓨터에 저장하는것이 불가능 ) -> 데이터를 일정량씩 슬레이브 노드로 분할하여 여러개의 컴퓨터에 분할 저장하고 다루게 된다. 여기서 Master Node로 나머지 Slave Node를 컨트롤하게 된다.
노드 = 3년정도 정상작동을 하는데 1만대를 기준으로 매일 1대의 노드에 장애가 발생했다.
구글은 2012년 100만개의 데이터 노드로 구성된 빅 데이터 시스템을 운영하였다.
데이터가 뻑나면 난리나니까 3대의 백업을 두자. 하는게 기본개념
26P에서의 Google File System 에 대한 서버 구조도를 확인할 수 있다.
27P Hadoop2
HDFS의 고 가용성
NAME Node 여러대를 운용한다.
모든 Name Node는 동기화되어 메타데이터 변화를 기록하는 로그 파일을 공유한다.
HDFS의 연합
다양한 Name Node서비스를 위해 서로 독립적인 네임스페이스를 갖는 NameNode를 수평적으로 확장
모든 data Node는 모든 nameNode의 namespace에 소속되며 모든 namespace의 block를 독립적으로 저장하게 된다.
Hadoop 2 Architecture
28P Name Node 는 Data Node가 어디에 존재하는지 데이터가 존재한다.
Secondary Name Node = 사이트 주소 www.어쩌구 등등
Resource Manager -> Application Manager , Sheduler 의 명령을 받아다가 Data Node에 각각 분할하여 일을 시킨다.
Node manager 의 Container = 데이터 리소스이다.
RDBMS, HDFS 의 차이점을 통해
왜 하둡에서 이러한 하둡 시스템을 사용을 했는지 이해하는것이 목표
| 관계형 데이터 베이스 (RDBMS) | 비 관계형 데이터 베이스(NoSQL) |
| 정형 데이터 트랜잭션 [ 행동에 관련된 데이터 ] 또는 중요 데이터 |
비정형 데이터 ( 텍스트 ) |
| 일관성 유효성 (A에 집중) | 분산 가능성, and(일관성 or 유효성)( P에 집중) |
| 안정성이 중요한 시스템에서 사용 | 대규모의 유연한 데이터 처리 |
| Oracle, IBM-DB@, MS SQL SErver, MySQL | BingTable(google), Dynamo(Amazon), Hbase(Yahoo), MongoDB, Cassandra |
CAP 이론
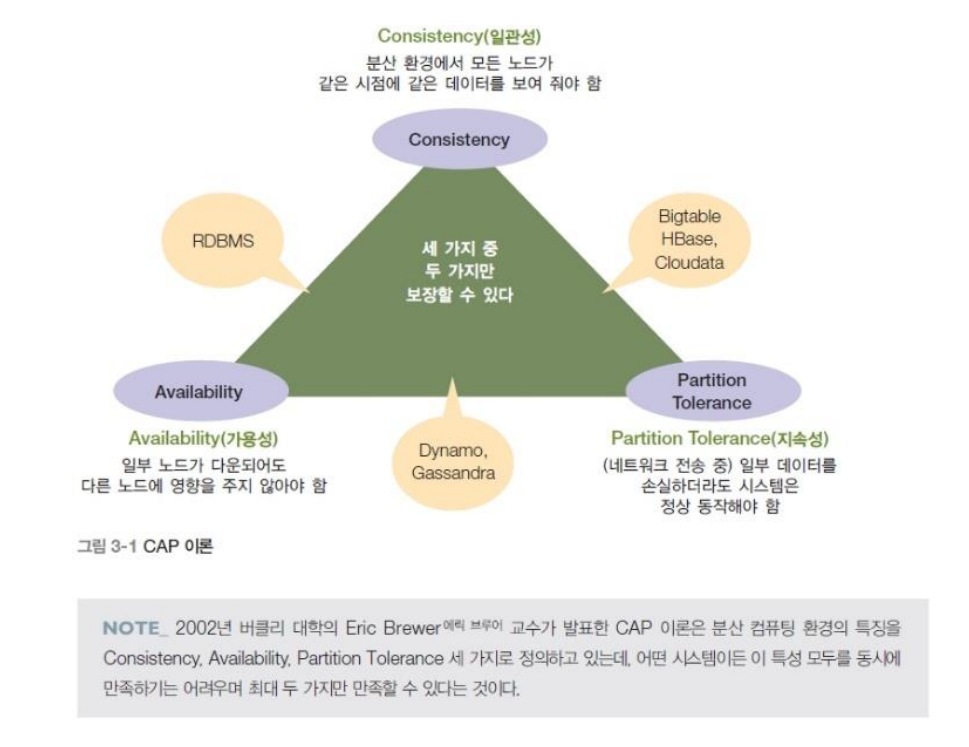
CAP이론 = 일관성, 가용성, 지속성의 3가지를 전부 만족시킬 수는 없다.
일관성 : 분산 환경에서 모든 노드가 같은 시점에 같은 데이터를 보여 줘아햠.
가용성 : 일부 노드가 다운되어도 다른 노드에 영향을 주지 않아야 함
지속성 : 일부 데이터를 손실하더라도 시스템은 정상 동작해야 함
RDBMS : 일관성, 가용성
Big table, HBase, Cloudata : 일관성, 지속성
Dynamo, Gassandra : 가용성, 지속성
NoSQL 데이터베이스의 주요 특징
Not Only SQL
비 관계형 데이터 베이스
테이블 스키마가 고정되어 있지 않음
<Key, Value>
put/get 연산 지원
- 기존의 RDBMS에서 제공하는 주요 기능을 지원하지 않음
- Sort 연산
- Join 연산
- Group By 연산
수평적 확장성
CAP 이론을 기준으로 한 RDBMS와 NoSQL의 비교

ACID = 원자성 일관성 독립성 지속성
Atomlclty 원자성
트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되면 안됨
Consistency 일관성
트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터를 제공
Isolatlon 독립성
트랜잭션 수행 시 다른 트랜잭션의 연산 작업이 끼어들면 안됨
Durability 지속성
성공적으로 수행된 트랜잭션은 영원히 반영되어야 함
RDMS = CA
NoSQL = AP, CP
NoSQL = 데이터의 무결성, 정확성 보장X
수정 삭제를 사용안함, 강한 이관성 불필요, 노드의 추가 및 삭제, 데이터 분산에 유연
RDBMS = 무결성, 정확성 보장
UPDATE, DELETE, Join 연산 가능, ACID 트랜젝션이 있음, 고정 스키마가 있음
No SQL 기술특징
스키마가 없음 : 데이터 저장방식에 고정된 데이터스키마가 없이 키로 접근함
탄력성 : 시스템 일부에 장애가 생겨도 클라이언트 시스템에 접근 가능
질의기능 : 수십 대에서 수천 대 규모로 구성된 시스템에서도 데이터의 특성에 맞게 처리 가능
캐싱 : 대규모 질의에도 고성능 응답속도를 제공할 수 있는 메모리 기반 캐싱 기술을 적용하는것이 중요
빅데이터 주요 저장 관리 및 기술
HDFS
MongoDB
HBase
Redis
ZooKeeper
| 제품/기술 | 최초 개발 | 최초 공개 | 주요기능 및 특징 |
| HDFS | 아파치 | 2008년 | 분산 환경에 맞는 데이터처리 |
| MongoDB |
NoSQL 분류
| 데이터 모델 | 설명 | 제품 예 |
| <키,값>저장구조 | 가장 간단한 데이터 모델 범위 질의 사용 어려움 응용 프로그램 모델링 복잡 |
아마존 DynamoDB 아마존 S3 |
| 문서 저장 구조 | 문서에는 다른 스키마가 있음 레코드[ 한줄 한줄 [행]] 간 관계설명 가능 개념적 RDBMS와 비슷 |
아마존 SimpleDB 아파치 CouchDB MongoDB |
| 열 기반 저장 구조 | 연관된 데이터 위주로 읽는데 유리한 구조 하나의 레코드 변경하려면 여려곳 수정 동일 도메인 열 값이 연속됨으로 압축 효율이 좋음 범위 질의에 유리 |
아파치 Cassandra |
전체적 구조 = SQL과 NoSQL간의 특징과 장단점 그리고 분류를 재정리 해야함.
키- 밸류 기반 NoSQL
대표적인 데이터 스토어
-REmote DiCtionary System [ REDIS ]
원격 사전 시스템/
메모리 기반의 key, Value 저장공간
간단한 형태의 NoSQL 데이터 베이스
인 메모리 솔루션
다양한 데이터 구조 지원
REDIS의 데이터 타입
string
최대 512MB까지 지원 문자만이 아닌 다른 이미지 바이러니 파일도 가능
set
-string의 집합
set간의 연산을 지원, 이로 교집합, 합집합 차집합등을 빨리 얻을 수 있음
stored set
일종의 가중치가 설정된 데이터 타입. 데이터 오른차순으로 내부정렬 정렬되어있어 score값 범위에 따른 질의 톱랭킹에 따른 질의 가능
hash
값 내의 필드 문자 쌍. RDBMS의 기본 키 한개와 문자열 필드 하나로 구성
list
문자열의 집합으로 저장되는 데이터 형태는 set과 비슷하지만 양방향 연결 리스트.

장점
- 다양한 데이터 타입 지원
- 데이터가 메모리에 있음으로 빠른 처리
- 독자적인 가상 메모리 기능을 추가하여 실제 메모리에 올릴 수 없는 데이터를 디스크에 적재 가능
- 오픈소스
단점
- 복잡한 기능 제공하지 않음
- 만들어진지 얼마 안되 사용방법, 해결책이 안나온 문제 발생 가능성있음
문서 기반 NoSQL
몽고 디비 [MongoDB]
대표적인 문서 지향 데이터 베이스
10gen이라는 회사가 오픈 소스로 개발한 것으로 상업적인 지원 가능
특징
스키마가 없는 데이터 베이스
- 별도로 스키마 정의 필요 없음
- 임의의 키 값에 대한 복잡한 검색 가능
관계형 데이터베이스에 비해 응답속도가 빠름
자동 샤딩(Auto Sharding)을 이용한 분산 확장 가능
[다른 노드에 복사 붙여넣기 자동확장 가능]
필요성
관계형 데이터베이스
앙케이트 응답, 로그 데이터같이 어떤 필드가 필요할 지 정의하기 어려운 경우에는 스키마 변경이 여러 번 변경이 발생할 수 있기 때문에 관계형 데이터 베이스를 사용하는 것이 불편함.
BTree 키 값, 포인터로 이진트리와 비슷한 데이터구조를 띈다.
MongoDB의 특징
조인 연산 불가능
Object에 다른 object를 끼워넣기 하여 어느정도 동일하게 조인 연산수행
배열 형식의 데이터를 입력하거나 검색 가능
데이터 베이스를 메모리에 저장하기 떄문에, 하드디스크에 저장하는 관계형 데이터 베이스에 비해 속도가 빠르다.
고나계형 데이터 베이스왇 오일하게 indexstructure를 사용하기 떄문에 빠르게 데이터 검색 가능
관계형 데이터베이스의 범위 질의 , 인덱스, 정렬, 맵리듀스 연산 지원
데이터는 BSON(JSON의 이진 형태) 형태로 저장 [ Abro와 같은 느낌 ]
C++ 프로그래밍 언어로 작성
도큐먼트 데이터 모델
P69
몽고DB와 DBMS의 차이점과 장단점을 비교하여 기억해야한다.
장점
스키마 정의 필요없어 필드 추가 등 변경이 없고 운영시 별도 작업이 필요하지 않음
다양한 조건을 가지고 검색 가능
대용량 데이터를 분산 저장하고 빠른 검색 지원
수평적 확장성 제공
오픈 소스
단점
Join이나 트랜잭션 연산 수행 불가
데이터 유실 가능성 있음
NotSQL의 각각의 특징,
CAP이론을 기억해야함
2가지만 만족할 수 있다.
분산환경에서는 = P에 집중
문서 형태가 RDBMS와 어떤 차이가 있는지 확인
Tree구조가 인기있는 이유는 일반적인 자료구조가 아닌 더 빠른 데이터 검색이 가능해서 인기가 있다.
키워드를 말하면 나열할 수 있게 바탕지식을 얻는식으로 공부해야한다.
'대학교 코딩공부 > 빅데이터 프로젝트' 카테고리의 다른 글
| 빅데이터 프로젝트 7주 [ Hadoob ] (0) | 2022.10.11 |
|---|---|
| 빅데이터 프로젝트 2번째 도커 설치 (1) | 2022.09.27 |
| 빅데이터 프로젝트 4주차 [ 웹 크롤링 ] (0) | 2022.09.22 |
| 빅데이터 프로젝트 4주차 [ 데이터 분류 ] (0) | 2022.09.22 |
| 빅데이터 프로젝트 4주차 [ 빅데이터 기본 ] (0) | 2022.09.20 |