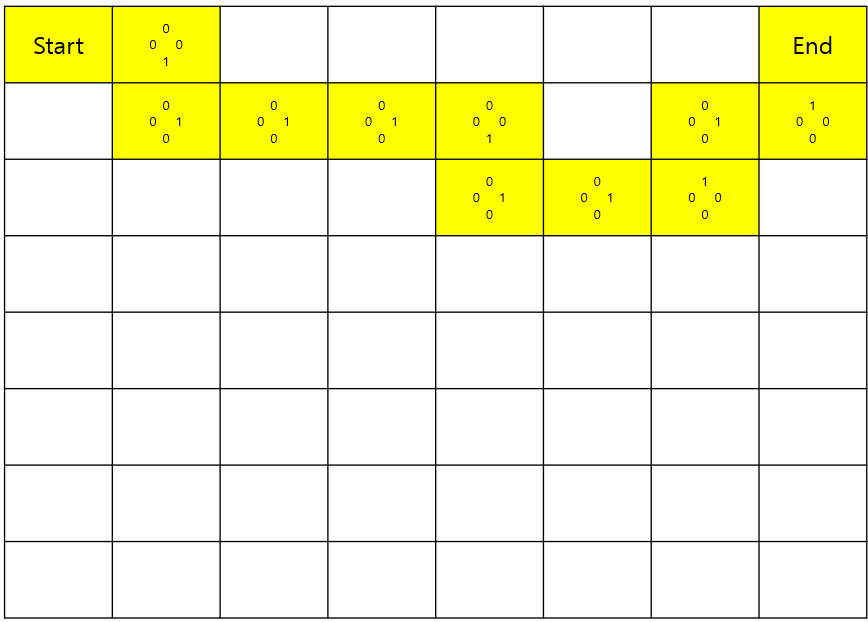
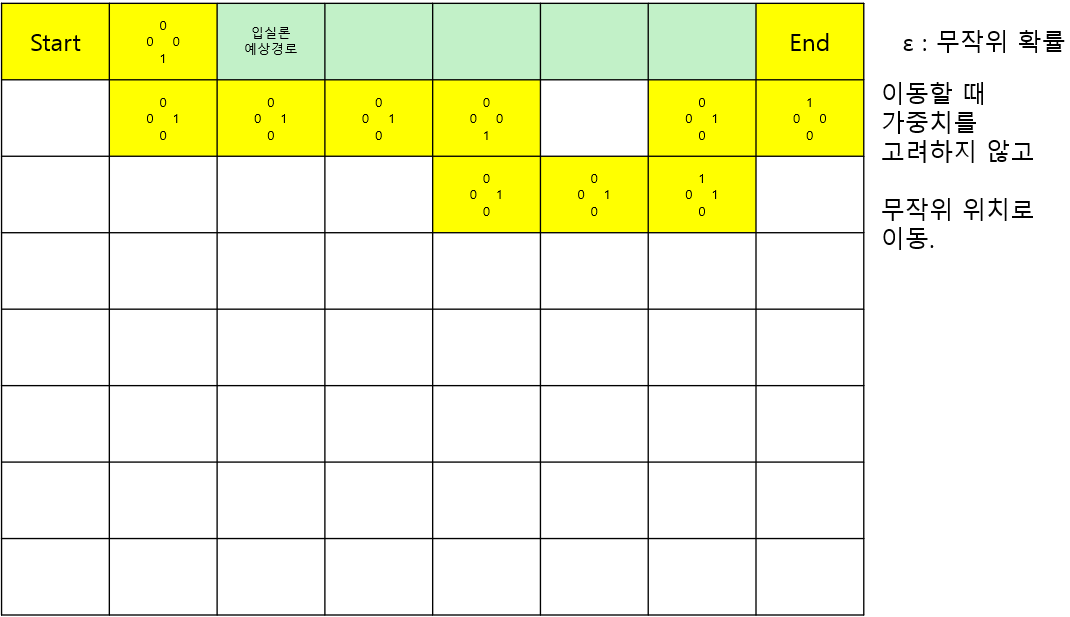
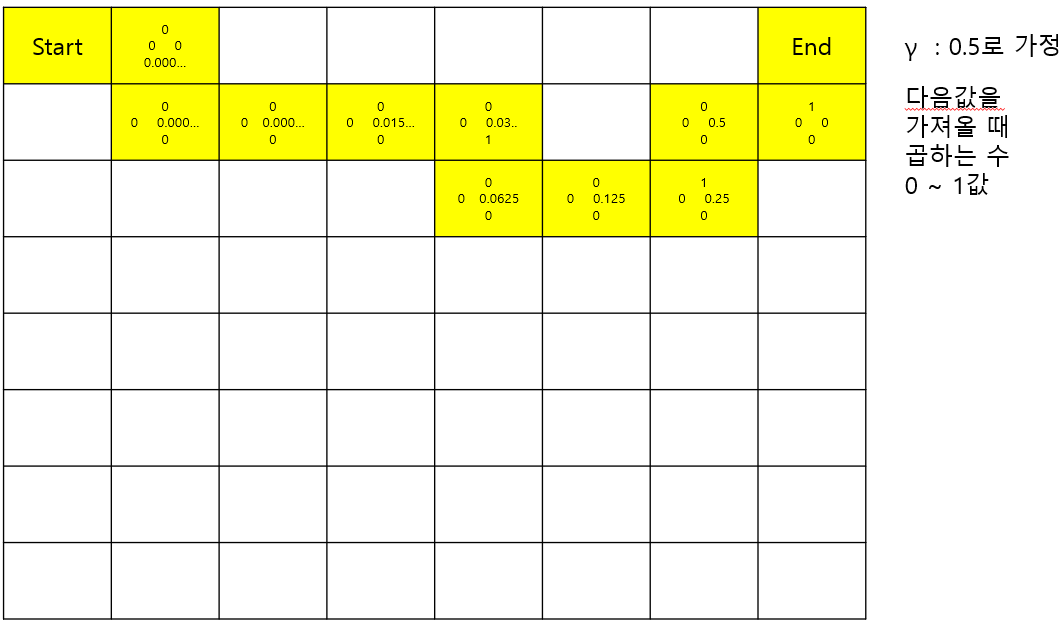
그레디언트 수식 계산방식들로 2가지에, 2가지의 장단점을 합친 한가지를 말할 수 있다.
Batch Gradient Descent
경사하강법의 한 스텝 업데이트 시 전체 트레이닝 데이터를 하나의 Batch로 만들어 사용하기 때문에 Batch Gradient Descent라고 부른다.
그레디언트 수식을 계산할 때, 100만개 이상의 매우 많은 손실함수 미분값을 전부 더한 뒤 평균을 취해서 파라미터를 업데이트 하게 되면 매우 큰 연산량 낭비가 일어난다.
한 스텝을 연산하는데 많은 시간이 걸리게 되고, 결과적으로 최적의 파라미터를 찾는데 오랜 시간이 걸린다.
옵티마이저 시간이 매우 길어지게 된다.
한 스텝 업데이트를 위해 계산하는 손실함수의 미분값은 아래 수식으로 나타낸다.
∂∂∂1J(θ0,θ1)=∂∂∂112n∑ni=1(^yi−yi)2
∂∂∂0J(θ0,θ1)=∂∂∂012n∑ni=1(^yi−yi)2
그에대한 반대적인 개념으로 경사하강법의 한 스텝 업데이트마다 1개의 트레이닝 데이터만 사용하는 기법을
Stochastic Gradient Descent 기법 이라고 한다.
Stochastic Gradient Descent
Stochastic Gradient Descent 기법 을 사용하면 파라미터를 자주 업데이트 할 수 있지만,
한번업데이트 할 때 전체 트레이닝 데이터의 특성을 고려하지 않고 각각의 트레이닝 데이터의 특성만을 고려하므로 부정확한 업데이트가 진행될 수 있다.
∂∂∂0J(θ0,θ1)=∂∂∂0(ˆy−y)2
∂∂∂1J(θ0,θ1)=∂∂∂1(ˆy−y)2
그리하여 실제 문제를 해결할 때 에는 두개의 절충 기법인 Mini-Batch Gradient Desent를 많이 이용한다.
Mini-Batch Gradient Desent는, 전체 트레이닝 데이터 Batch가 1000(n)개라면 이를 100(m)개씩 묶은 Mini-Batch개수만큼의 손실 함수 미분값 평균을 이용해서 파라미터를 한 스텝을 업데이트하는 기법이다.
Mini-Batch Gradient Desent 기법에서 한 스텝 업데이트를 위해 계산하는 손실 함수의 미분값은 아래 수식으로 나타낼 수 있다.
∂∂∂0J(θ0,θ1)=∂∂∂012m∑mi=1(^yi−yi)2
∂∂∂1J(θ0,θ1)=∂∂∂112m∑mi=1(^yi−yi)2
'알고리즘' 카테고리의 다른 글
| Training Data, Validation Data, Test Data (0) | 2024.06.13 |
|---|---|
| Overfitting 과 Underfitting (0) | 2024.06.13 |
| 머신러닝 프로세스 ( 선형회귀 ) (0) | 2024.06.13 |
| Q & Optimal Policy (1) | 2024.06.09 |
| MDP ( Markov Decision Process ) (1) | 2024.06.09 |