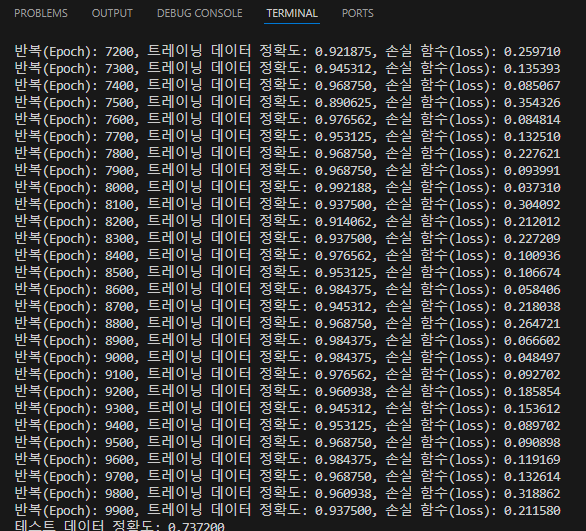
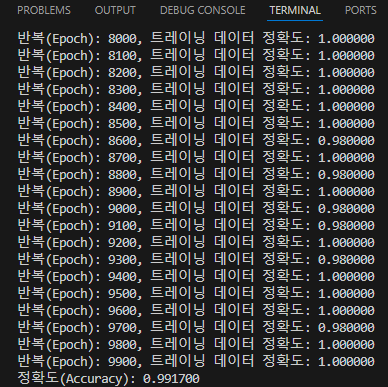
순환신경망 (RNN)[Recurrent Neural Network]은 자연어 처리문제와 시계열 데이터를 다루기에 최적화된 인공신경망이다. 시계열 데이터시간 축을 중심으로 현재 시간의 데이터가 이전 및 이후 시간의 데이터와 연관관계를 가지는 데이터.예 : 주식 가격, 음성 데이터, 자연어 데이터 등.. 주식을 예로 들면오늘의 주식 가격은 어제의 주식 가격과 연관되어있고,내일의 주식 가격은 오늘의 주식 가격과 연관관계가 있다. 따라서 주식 가격은 시계열 데이터로 볼수 있다. RNN 구조 기본 개념기본적인 인공신경망(ANN) 구조에 이전 시간의 은닉층 출력값을 현재 시간의 입력값으로 사용하는 경로가 추가된 형태이다.이러한 순환 구조는 시간에 따라 데이터를 처리하고 이전 상태의 정보가 현재와 미래 상태에 영향을..
대표적인 Regulazation 기법이다. 오버피팅(OverFitting)을 방지할 수 있도록 만들어주는 기법을 총칭해서 Regularization기법 이라고 부른다. 드롭아웃(Dropout)은 대표적인 Regularization 기법 중 하나이다. 드랍아웃 기법은 학습 과정에서 일부 노드를 사용하지 않는 형태로 만들어서오버 피팅(OverFitting) 을 방지할 수 있도록 만들어주는 Regularization기법이다. 학습할 때 범위를 랜덤하게 설정해서, 일부 노드를 덜어낸다 라고 이해하면 된다.이렇게 덜어냄으로써 일정부분만 학습하게 되면 트레이닝데이터 에서만 정확도가 높아지는걸 방지할 수 있다. TrainingData에 대해서는 오버피팅을 방지하기 위해서는 드랍아웃을 수행하지만, TestData에 ..
컨볼루션 신경망(CNN) 컨볼루션 신경망은 이미지 분야를 다루기에 최적화된 구조이다. 컨볼루선 신경망은 크게 컨볼루션층(COnvolution Layer)과 풀링층(Polling[Subsampling])Layer로 구성된다.풀링은 서브샘플링 이라고 불린다. 컨볼루션 층에서 이루어지는 동작3x3커널을 이용해서 5x5크기의 이미지 행렬에 컨볼루션 연산을 수행하는 과정이다. 입력에 해당되는 커널의 값을 1만큼, 0이라면 0을 곱해서 나온 모든 결과를 더해서 출력위치에 넣어서 압축하는것이다. 원본이미지에 커널을 이용해서 컨볼루션을 수행하면 커널의 종류에 따라 원본 이미지의 특징들이 화설화 맵으로 추출되게 한다. 이때 어떤 커널을 사용하느냐에 따라 원본 이미지에서 다양한 특징을 추출할 수 있다.이미지 노이즈처리를 ..
컴퓨터 비전, 즉 컴퓨터가 이미지를 인식하고 이해하는 과정은 여러 가지 어려움이 있다. 밝기 변화사진을 찍는 환경에 따라 이미지의 밝기가 달라질 수 있다.예를 들어, 같은 물체라도 낮에 찍은 사진과 밤에 찍은 사진은 매우 다르게 보일 수 있다.변형물체는 다양한 각도와 거리에서 찍힐 수 있습니다. 예를 들어, 고양이는 옆모습, 정면, 또는 뒤에서 찍힐 수 있으며, 이는 이미지 인식의 어려움을 가중시킨다. 배경 장애 물체와 배경이 복잡하게 섞여 있는 경우, 배경의 복잡함이 물체 인식을 방해할 수 있다.가림물체의 일부가 다른 물체에 의해 가려질 수 있다.예를 들어, 나무 뒤에 숨어 있는 고양이를 인식하는 것은 일부만 보이기 때문에 어려울 수 있다. 인트라클래스 바리에이션 같은 종류의 물체라도 형태가 다를 수 ..
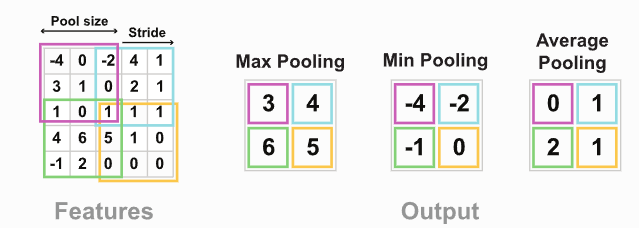
최대값 풀링은 이미지의 X x X크기 부분에서 가장 큰 값(Max Value)하나를 추출해서 원본 이미지의 X x X개의 값을 1개의 값으로 축소한다.
동일한 원리로 평균값 풀링, 최소값 풀링은 평균값, 최소값으로 축소한다.
풀링층 역시 이미지의 좌측 상단에서 우측 하단으로 순차적으로 전체 이미지에 대해 풀링을 수행한다.
풀링 예시
풀링 수행과정을 보자.
풀링층은 크게 2가지 장점이 있다.
이미지의 차원을 축소함으로써 필요한 연산량을 감소시킬 수 있고, 이미지의 가장 강한 특징만을 추출하는 특징 선별 효과가 있다.
예를들어, 모서리만 추출된 활성화 맵에서 최대값 풀링을 수행하면, 차원은 축소되고 흐릿하던 모서리 부분이 더욱 뚜렷해질 것이다.
컨볼루션층을 거치면 인풋 이미지의 가로, 세로 차원이 축소된다.
구체적으로 인풋 이미지의 가로 길이가 $ W_{in} $ 이라면, 컨볼루션 층을 거친 출력 이미지의 가로 길이 $ W_{out} $ 은 다음과 같이 계산된다.
$ W_{out} = \frac{W_{in} - F + 2P}{S} + 1 $
여기서 F는 필터의 크기, S는 스트라이드 를 의미한다.
스트라이드
스트라이드는 컨볼루션 연산 시 건너뛰는 정도를 나타낸다.
만약, 스트라이드를 크게 잡아서 이미지를 성큼성큼 건너뛰어서 컨볼루션을 수행하면 차원이 많이 축소되고, 스트라이드를 작게 잡아서 이미지를 촘촘히 건너뛰면 차원이 조금 축소된다.
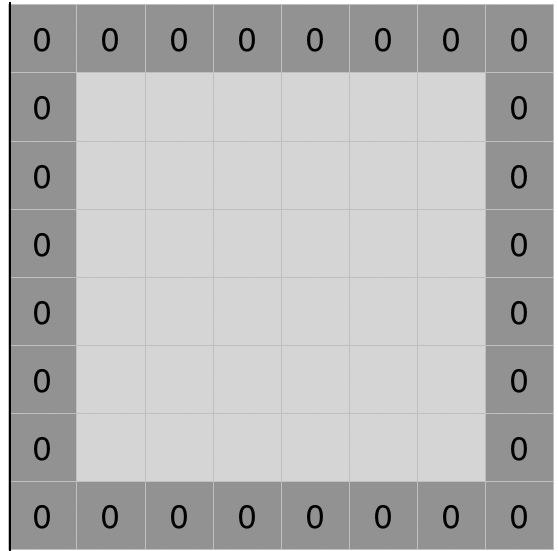
또한 $ \frac{W_{in} - F + 2P}{S} $ 의 차원이 정수로 나누어 떨어지지 않을 수도 있기 때문에 인풋 이미지의 상하좌우 모서리에 P만큼 0을 채워주는 제로패딩 을 P만큼 적용해준다.
제로패딩
마찬가지로, 인풋 이미지의 세로 길이가 $ H_{in} $ 이라면 컨볼루션층을 거친 출력 이미지의 세로길이 $ H_{out} $ 은 아래와 같이 계산된다.
$ H_{out} = \frac{H_{in} - F + 2P}{S} + 1 $
컨볼루션 층의 출력결과의 3번째 차원은 컨볼루션 필터 개수가 K가 된다.
따라서 컨볼루션층의 결과로 출력되는 차원은 $ [W_{out}, H_{out}, K] $ 이다.
예를 들어 [28x28x1] MINST이미지에 4X4크기의 필터 (F=4)에 스트라이드가 2(S=2)이고 제로패딩을 1만큼 적용한(P = 1), 64개의 필터개수(K=64)를 가진 컨볼루션 층을 적용하면 출력 결과로 [14, 14, 64], 즉, 14X14크기의 64개의 활성화맵 이 추출될것이다.