728x90
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# MNIST 데이터를 다운로드
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train.astype('float32'), x_test.astype('float32')
x_train, x_test = x_train.reshape([-1, 784]), x_test.reshape([-1, 784])
x_train, x_test = x_train / 255., x_test / 255.
learning_rate = 0.02
training_epochs = 50 # 반복 횟수
batch_size = 256 # 배치 개수
display_step = 1 # 손실함수 출력 주기
examples_to_show = 10 # 보여줄 MNIST Reconstruction 이미지 개수
input_size = 784 # 28*28
hidden1_size = 256
hidden2_size = 128
# tf.data API를 이용해서 데이터를 섞고 batch 형태로 가져온다.
train_data = tf.data.Dataset.from_tensor_slices(x_train)
train_data = train_data.shuffle(60000).batch(batch_size)
def random_normal_initializer_with_stddev_1():
return tf.keras.initializers.RandomNormal(mean=0.0, stddev=1.0, seed=None)
# tf.keras.Model을 이용해서 Autoencoder 모델 정의
class AutoEncoder(tf.keras.Model):
def __init__(self):
super(AutoEncoder, self).__init__()
# 인코딩(Encoding) - 784 -> 256 -> 128
self.hidden_layer_1 = tf.keras.layers.Dense(hidden1_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
self.hidden_layer_2 = tf.keras.layers.Dense(hidden2_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
# 디코딩(Decoding) 128 -> 256 -> 784
self.hidden_layer_3 = tf.keras.layers.Dense(hidden1_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
self.output_layer = tf.keras.layers.Dense(input_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
def call(self, x):
H1_output = self.hidden_layer_1(x)
H2_output = self.hidden_layer_2(H1_output)
H3_output = self.hidden_layer_3(H2_output)
reconstructed_x = self.output_layer(H3_output)
return reconstructed_x
# MSE 손실함수를 정의한다.
@tf.function
def mse_loss(y_pred, y_true):
return tf.reduce_mean(tf.pow(y_true - y_pred, 2))
# 최적화를 위한 RMSProp 옵티마이저 정의
optimizer = tf.optimizers.RMSprop(learning_rate)
# 최적화를 위한 function을 정의
@tf.function
def train_step(model, x):
# 타겟데이터는 인풋데이터 와 같다.
y_true = x
with tf.GradientTape() as tape:
y_pred = model(x)
loss = mse_loss(y_pred, y_true)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
# Autoencoder 모델 선언.
AutoEncoder_model = AutoEncoder()
# 지정된 횟수만큼 최적화를 수행
for epoch in range(training_epochs):
for batch_x in train_data:
loss = train_step(AutoEncoder_model, batch_x)
# 지정된 epoch마다 학습결과 출력.
if epoch % display_step == 0:
print("반복(Epoch): %d, 손실함수(Loss): %f" % (epoch + 1, loss))
# 테스트 데이터로 Reconstruction을 수행한다.
reconstructed_result = AutoEncoder_model(x_test[:examples_to_show])
# 원본 MNIST 데이터와 Reconstruction 결과를 비교.
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(x_test[i], (28, 28)), cmap='gray')
a[1][i].imshow(np.reshape(reconstructed_result[i], (28, 28)), cmap='gray')
f.savefig('reconstructed_mnist_image.png') # reconstruction 결과를 png로 저장.
plt.show()
plt.draw()
plt.waitforbuttonpress()

코드를 분할해서 이해해보자.
1.MNIST 데이터 준비
# MNIST 데이터를 다운로드
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train.astype('float32'), x_test.astype('float32')
x_train, x_test = x_train.reshape([-1, 784]), x_test.reshape([-1, 784])
x_train, x_test = x_train / 255., x_test / 255.
MNIST데이터셋을 다운로드하고 준비한다. MNIST는 0부터 9까지의 숫자이미지 로 구성된 데이터셋이다.
- tf.keras.datasets.mnist.load_data()를 사용해 데이터를 로드한다.
- 이미지를 28x28크기의 2D배열에서 784크기의 1D배열로 변환한다.
- 각 픽셀 값을 0 ~ 255 범위에서 0~1범위로 정규화한다.
2.하이퍼 파라미터 설정
learning_rate = 0.02
training_epochs = 50 # 반복 횟수
batch_size = 256 # 배치 크기
display_step = 1 # 손실 함수 출력 주기
examples_to_show = 10 # 보여줄 MNIST Reconstruction 이미지 개수
input_size = 784 # 28*28
hidden1_size = 256
hidden2_size = 128
모델 학습에 필요한 여러 설정 값을 지정한다.
- learning_rate: 학습 속도
- training_epochs: 학습 반복 횟수
- batch_size: 한 번에 학습할 데이터 크기
- display_step: 손실 함수 출력 주기
- examples_to_show: 나중에 보여줄 재구성된 이미지 개수
- input_size: 입력 이미지의 크기
- hidden1_size, hidden2_size: 은닉층의 뉴런 개수
3.데이터 셋 준비
# tf.data API를 이용해서 데이터를 섞고 batch 형태로 가져온다.
train_data = tf.data.Dataset.from_tensor_slices(x_train)
train_data = train_data.shuffle(60000).batch(batch_size)
데이터를 섞고 배치 크기로 나누어 학습에 사용한다.
- shuffle(60000): 데이터셋을 섞는다.
- batch(batch_size): 데이터를 batch 크기로 나눈다.
4.모델 정의
def random_normal_initializer_with_stddev_1():
return tf.keras.initializers.RandomNormal(mean=0.0, stddev=1.0, seed=None)
# tf.keras.Model을 이용해서 Autoencoder 모델 정의
class AutoEncoder(tf.keras.Model):
def __init__(self):
super(AutoEncoder, self).__init__()
# 인코딩(Encoding) - 784 -> 256 -> 128
self.hidden_layer_1 = tf.keras.layers.Dense(hidden1_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
self.hidden_layer_2 = tf.keras.layers.Dense(hidden2_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
# 디코딩(Decoding) 128 -> 256 -> 784
self.hidden_layer_3 = tf.keras.layers.Dense(hidden1_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
self.output_layer = tf.keras.layers.Dense(input_size,
activation='sigmoid',
kernel_initializer=random_normal_initializer_with_stddev_1(),
bias_initializer=random_normal_initializer_with_stddev_1())
def call(self, x):
H1_output = self.hidden_layer_1(x)
H2_output = self.hidden_layer_2(H1_output)
H3_output = self.hidden_layer_3(H2_output)
reconstructed_x = self.output_layer(H3_output)
return reconstructed_x오토인코더 모델을 정의한다.
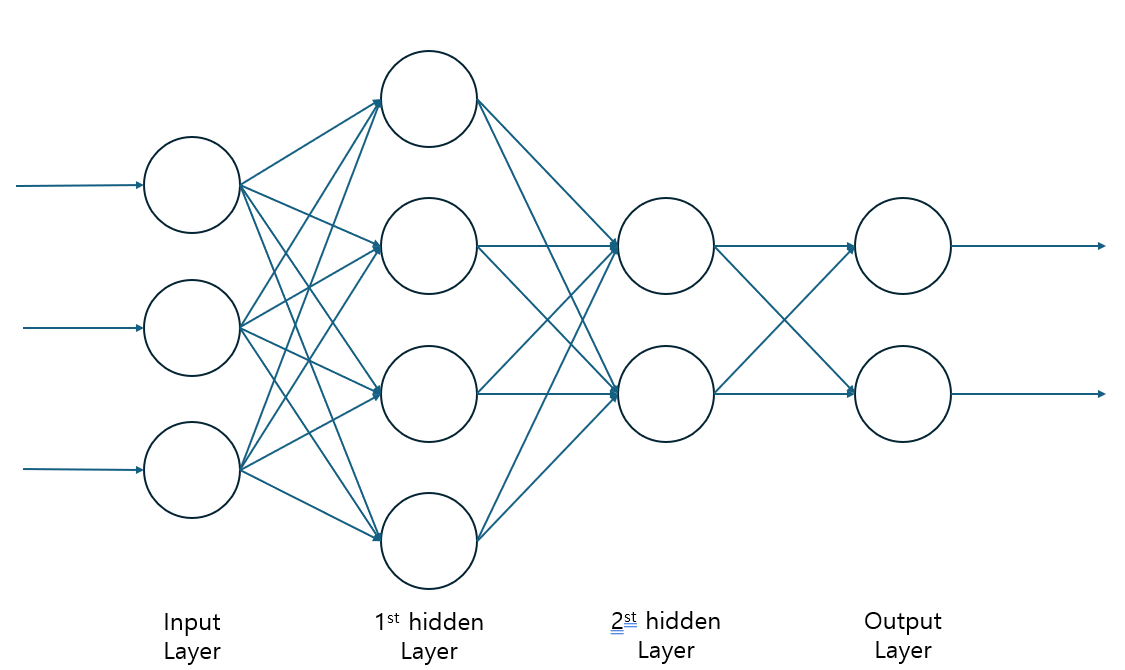
오토인코더는 입력 데이터를 인코딩했다가. 다시 디코딩하여 원래 데이터와 비슷하게 재구성하는 모델이다.
- hidden_layer_1: 첫 번째 은닉층, 784 -> 256
- hidden_layer_2: 두 번째 은닉층, 256 -> 128
- hidden_layer_3: 세 번째 은닉층, 128 -> 256
- output_layer: 출력층, 256 -> 784
- call 메소드: 모델이 데이터를 처리하는 방법을 정의한다.
H1output이 H2output으로 들어가고를 반복하여 reconstructed_x로 출력된다.
5. 손실 함수 및 옵티마이저 정의
# MSE 손실함수를 정의한다.
@tf.function
def mse_loss(y_pred, y_true):
return tf.reduce_mean(tf.pow(y_true - y_pred, 2))
# 최적화를 위한 RMSProp 옵티마이저 정의
optimizer = tf.optimizers.RMSprop(learning_rate)학습 과정에서 사용할 손실함수 와 옵티마이저를 정의한다.
- mse_loss: 평균 제곱 오차(MSE)를 손실 함수로 사용한다.
- optimizer: RMSProp 옵티마이저를 사용하여 모델을 최적화한다.
6. 학습과정 정의
# 최적화를 위한 function을 정의
@tf.function
def train_step(model, x):
# 타겟데이터는 인풋데이터와 같다.
y_true = x
with tf.GradientTape() as tape:
y_pred = model(x)
loss = mse_loss(y_pred, y_true)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss학습 과정에서 각 배치에 대해 모델을 최적화하는 방법을 정의한다.
- train_step: 한 단계 학습을 수행하는 함수입니다
- GradientTape: 손실에 대한 그래디언트를 계산합니다.
- optimizer.apply_gradients: 계산된 그래디언트를 사용하여 모델의 가중치를 업데이트합니다.
7. 모델 학습
# Autoencoder 모델 선언.
AutoEncoder_model = AutoEncoder()
# 지정된 횟수만큼 최적화를 수행
for epoch in range(training_epochs):
for batch_x in train_data:
loss = train_step(AutoEncoder_model, batch_x)
# 지정된 epoch마다 학습결과 출력.
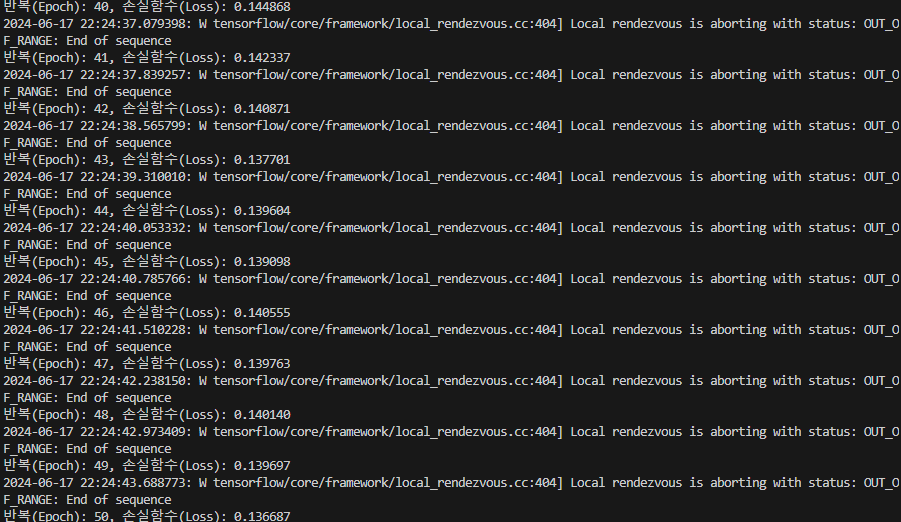
if epoch % display_step == 0:
print("반복(Epoch): %d, 손실함수(Loss): %f" % (epoch + 1, loss))모델을 학습시킨다.
- 각 epoch 동안 데이터셋의 각 배치에 대해 train_step을 호출하여 모델을 최적화한다.
- 매 display_step마다 현재 에폭과 손실 함수를 출력한다.
8. 결과 확인
# 테스트 데이터로 Reconstruction을 수행한다.
reconstructed_result = AutoEncoder_model(x_test[:examples_to_show])
# 원본 MNIST 데이터와 Reconstruction 결과를 비교.
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(x_test[i], (28, 28)), cmap='gray')
a[1][i].imshow(np.reshape(reconstructed_result[i], (28, 28)), cmap='gray')
f.savefig('reconstructed_mnist_image.png') # reconstruction 결과를 png로 저장.
plt.show()
plt.draw()
plt.waitforbuttonpress()테스트 데이터를 사용하여 모델이 입력 데이터를 얼마나 잘 재구성하는지 확인한다.
위 과정을 통해 오토인코더 모델이 데이터를 압축했다가 다시 복원하는 능력을 학습하게 된다.
모델이 잘 학습되면 재구성된 이미지가 유사하게 나타난다.

728x90
'알고리즘' 카테고리의 다른 글
| 컨볼루션(COnvolution), 풀링(Polling) (0) | 2024.06.18 |
|---|---|
| CNN기반 컴퓨터비전처리 (0) | 2024.06.17 |
| 오토인코더(Autoencoder) (0) | 2024.06.16 |
| TensorFlow 2.0을 이용한 ANN MNIST 숫자분류기 구현 (0) | 2024.06.16 |
| 인공신경망(Artificial Neural Networks[ANN]) (1) | 2024.06.15 |