
퍼셉트론
이전에 인공신경망의 개념을 제안하였지만, 개념적인 시도로써 공학적인 구현을 최초로 제안한 개념
무려 1958년에 나온 논문이다.
퍼셉트론 은 생물학적 뉴런을 공학적인 구조로 변형한 그림이다.
퍼셉트론은 입력층(Input [ in(t) ] )와 출력층(Output [ out(t) ] ) 을 가진다.
퍼셉트론은 입력층에서 인풋데이터 X를 받고 이를 가중치 W와 곱한 후 이 값에 바이어스 b를 더한다.
이 값을 활성함수 (시그모이드 함수) 의 입력값으로 대입해서, 출력층은 최종적으로 0 또는 1의 값으로 출력한다.

활성함수는 계단함수를 사용해서 0보다 작으면 0 크면 1 이런식으로 0 또는 1로 표현하게 한다.
W는 가중치를 의미한다.
의사결정에 대한 값은 X라고 할때
W1 ~ Wn까지는 임의의 가중치 이다.
고려사항을 Perceptron의 input에 넣을 수 있다.
( 어떤 행동을 할 때 확인해야할 조건문 )
퍼셉트론은 지금의 딥러닝 화제처럼, 실제 인간과 같은 인공지능을 만들 수 있을것이라는 기대를 받았으나,
퍼셉트론은 단순한 선형 분류기에 불과하며 단순한 XOR문제도 해결할 수 없다는 사실을 수학적으로 증명하면서 인기가 사라졌다.
즉, 퍼셉트론은 선형분류이기 때문에, 직선 한개로 구분하지 못하는 상황은 해결할 수 없다는 시사점이 있다.
다층 퍼셉트론 MLP( Mutli - Layer Perceptron ) = 인공신경망 ( ANN )
( 퍼셉트론 개선 )
인공신경망 대신 논리적인 추론을 이용하는 방법으로 연구했다. 퍼셉트론을 여러층으로 쌓아올린 다층 퍼셉트론(Multi - Layer Perceptron(MLP)가 나타났다.
다중 퍼셉트론을 이용하면 선형 분리가 불가능한 문제도 해결할 수 있다는 사실이 밝혀졌다.
ANN이라는 용어를 사용할때 일반적으로는 다층 퍼셉트론을 의미한다.
다층 퍼셉트론은 입력층, 은닉층, 출력층 으로 구성되어있으며, 은닉층 은 입출력과정에서 직접적으로 보이지는 않지만 숨겨진 특징을 학습하는 역할을 한다.
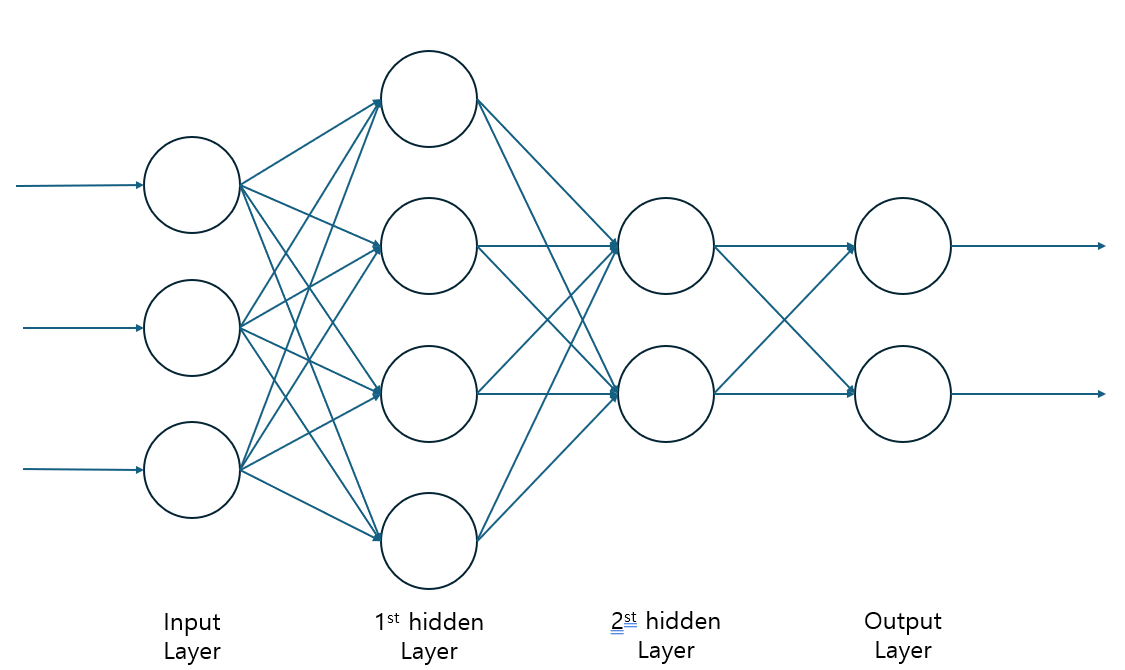
위 다층 퍼셉트론을 한부분만 보면 퍼셉트론 한개가 보이는걸 볼 수 있다.
이러한 다층 퍼셉트론은 퍼셉트론을 여러개 겹쳐놓은것 이라고 이해하면 된다.
이러한 다층 퍼셉트론은 활성 함수로 계단함수 가 아닌 비선형 함수인 시그모이드 와 쌍곡 탄젠트혹은 ReLU를 사용한다.
활성함수의 출력 결과인 y를 활성값 Activation이라고 부른다.
과거에는 Sigmoid함수를 많이 사용하였지만, 최근에는 ReLU가 딥러닝 학습에 더 적합하다고 알려져서 ReLU를 더 많이 사용하는 추세이다.
배니싱 그레디언트 프라브럼 문제를 해결하기 위해서 ReLu를 사용한다.
그레디언트 는 결국 미분값 이다. 여기서 시그모이드 함수의 차트상, 일정 범위를 벗어나게 되면 0으로 빠져버려서 값이 무시되는 문제가 발생한다.
ReLu의 경우 0보다 작으면 무조건 미분값이 0으로 빠지지만, ReLu의 경우 0보다 크다면, 항상 위로 수렴하기 때문에 값이 무시되지 않는다.
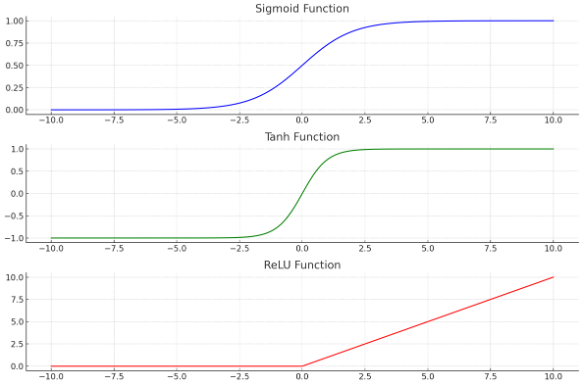
위 그래프를 보고 이해해보자.
시그모이드 함수 (Sigmoid Function)
σ(x)=11+e−x
특징으로는 출력값을 0 과 1사이에 위치하게 하며, 입력값이 커질 수록 1에 가까워지고 입력값이 작아질수록 0에 가까워지게 한다.
매우 큰 양수나, 음수 값에서 그래디언트가 거의 0에 가까워지는 배니싱 그라디언트 문제가 발생.
쌍곡 탄젠트 함수(Tanh Funtion)
tanh(x)=ex−e−xex+e−x
특징으로는 출력값이 -1과 1사이에 위치하며 중심이 0이라서 시그모이드 함수보다 학습이 잘 되는 경우가 많다.
시그모이드 함수와 유사하게 큰 양수나 음수에서 그래디언트가 거의 0에 가까워지는 배니싱 그라디언트 문제가 발생
ReLU함수(Rectified Linear Unit Function)
ReLU(x)=max(0,x)
출력값이 0 또는 입력값 자체가 된다. 음수 입력값에 대해서는 0을 출력하고, 양수는 그대로 출력한다.
배니싱그라디언트 문제를 완화할 수 있다. 양수 입력에 대해서는 그래디언트가 0이 아님으로, 신경망의 깊은층 학습이 잘 이루어진다.
음수 입력값이 많을 경우 뉴런이 죽어버리는 다잉ReLU문제가 발생할 수 있다.
'알고리즘' 카테고리의 다른 글
| 오토인코더(Autoencoder) (0) | 2024.06.16 |
|---|---|
| TensorFlow 2.0을 이용한 ANN MNIST 숫자분류기 구현 (0) | 2024.06.16 |
| TensorFlow2.0으로 MNIST 숫자분류기 구현 (1) | 2024.06.14 |
| 소프트맥스 회귀(Softmax Regression) (1) | 2024.06.13 |
| One-hot Encoding (0) | 2024.06.13 |