BruteForce
무차별 대입법(BruteForce) 은 완전탐색 알고리즘 으로, 가능한 모든 경우의 수를 전부 탐색하여
정확한 해답을 찾는 방법이다. 이 방법은 모든 가능한 조합을 검사하기 때문에, 시간이 오래걸림으로
큰 입력값, 매우 넓은 범위를 탐색하는것 에 대해서는 매우 비효율적이다.
그러나, 직관적인 방식으로 탐색하기 때문에 쉽게 문제를 해결할 수 있다.
다음은 BruteForce를 구현한 알고리즘으로, 10개의 숫자중 8개의 숫자를 더했을 때 100이 나오는 경우를 구하는 코드 이다.
#include <iostream>
#include <list>
using namespace std;
// 무식하게 탐색한다.
// 완전탐색 알고리즘.
// 모든 경우의 수를 전부 탐색한다.
// 백트래킹 = 의미없는 경우는 제외하고 전부 탐색한다.
// 진행하는게 의미없는 조건을 찾아야 한다.
// 제외해줘야 하기 때문에 처리 자체가 불가능 해질 수 있다.
/*
10개의 숫자가 있다.
7 15 21 8 14 25 10 11 17 5
이 중 숫자가 딱 100이 되는 8개의 숫자 찾기
예외처리 해주면서,
어떻게 해줘야 최대한 이 반복문을 줄일 수 있는지 생각해보기.
의미 없는 경우
배열은 먼저 sort한 뒤, 작은숫자대로 더한다.
그러나 남은 덧셈 수가 남아있는수 보다 작을 경우 의미가 없기 때문에 전 수는 빼낸다.
빼낸 뒤 나머지를 덧셈 해준다.
왼쪽부터 오른쪽까지 다 계산해야한다.
왼쪽부터 다 더하면서 가다가 결과가 안나왔을 시 전 것을 빼고 바로 다음꺼를 더해서 계산
순방향 정렬을 한 뒤 완전탐색을 시도하였을 경우,
임의의 모든 값을 순환시키는것 보다 약 O^n/2 만큼 더 줄어들 수 있다.
*/
auto Chack_dup(int arr[] ,int size ,int a) -> bool
{
for (int i = 0; i < size; i++)
if (arr[i] == a) return false;
return true;
}
auto Array_Sum(int arr[], int size) -> int
{
int result = 0;
for (int i = 0; i < size; i++) result += arr[i];
return result;
}
auto PRINT(int arr[], int size, string str) -> void
{
cout << str;
for (int i = 0; i < size; i++) {
if (arr[i] != 0) cout << arr[i] << " ";
}
cout << "\tSUM : " << Array_Sum(arr, size) << endl;
}
auto BruteForce(int arr[], int start, int end, int count = 0) -> bool
{
static int result[8] = { 0 };
static int stic_i = 0;
// 10^10 차원의 8개의 점으로 이루어진 선 한줄을 찾아야한다.
for (int i = start; i <= end; i++) { // 10^10차원을 제귀를 통해 전개한다.
if (count == 8) break; // count == 8 이 됨은, 들어간 배열이 가득 찼다는 의미이다. 그럼으로 전개된 차원을 탈출
if (Chack_dup(result, 8, arr[i])) { // 중복값을 체크하여, 현재값에 진입해 있는지 확인한다.
result[count] = arr[i]; // 현재 차원위치에 지정된 값을 삽입해준다.
BruteForce(arr, start + 1, end, count + 1); // 재귀를 사용하여 다음 차원위치로 이동해준다.
}
}
int Asum = Array_Sum(result, 8); // 현재 결과에 있는 모든 데이터를 더해준다.
if (Asum == 100) { // 모든 데이터를 더했을 때 100이 나올경우,
PRINT(result, 8, "RESULT : "); exit(0); // 결과를 출력해주고 1을 반환한다.
}
if (start >= end) { return 0; }
// start가 end보다 크거나 같을경우, 10^10 차원순환이 전부 완료되었을 경우,
// 순환완료한 재귀의 기입된 배열데이터는 의미가 없어지기 때문에 0을 반환하고 종료해준다.
else if (Asum != 100 && count == 8) {
// Asum 이 100이 아니고 count가 8일경우, 위의 if문에 해당이 안되기 때문에 차원순환이 전부 종료되지 않아
// 남은 차원을 전부 순환시켜주어야 한다.
result[count] = 0; // 현재 가득 찬 배열은 100을 만들어내지 못함으로 0으로 초기화시켜준다.
BruteForce(arr, start + 1, end, count - 1);
// 현재 남은 배열을 전부 순환시켜주기 위해 count를 1 줄여 마지막 값을 다음으로 넘길 수 있게 하고,
// 다음 배열위치로 넘겨준다.
}
return 0;
}
int main()
{
int arr[] = { 7, 15, 21, 8, 14, 25, 10, 11, 17, 5 };
BruteForce(arr,0, 9);
return 0;
}
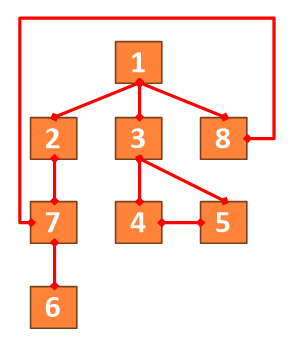
Depth_first_search
그래프를 탐색하는 알고리즘 중 하나로, 시작 노드 에서 탐색을 시작하여, 다음 노드로 계속해서 탐색을 진행하며,
더이상 탐색할 수 없는 상태까지 깊이 들어가면 이전 단계로 돌아와, 다른 경로를 탐색한다.
이것을 반복하여 그래프를 탐색하는 방식이다.
DFS 알고리즘의 특징은 다음과 같다.
- 깊이 우선 탐색은 스택 또는 재귀 함수를 사용하여 구현할 수 있다.
- 탐색 도중에 더이상 가갈 수 없는 경로가 없다면, 이전단계로 돌아가 다른 경로를 탐색한다.
- DFS는 깊이에 우선순위를 두기 때문에 시작 노드와 가까운 노드를 먼저 탐색하게 된다.
DFS 알고리즘의 장점은 다음과 같다.
- 구현이 간단하고, 직관적이다.
- 노드를 방문하는 순서를 추적할 수 있음으로 경로를 복구하는데 유효하다.
- 그래프에서 연결된 모든 구성요소를 탐색할 수 있다.
DFS 알고리즘의 단점은 다음과 같다.
- 그래프에 순환 경로가 있는 경우, 무한루프에 빠질 수 있다.
- 그래프가 매우 깊거나 무한한 경우, 탐색경로가 길어지기 때문에 스택 오버플로우(Stack Overflow)가 발생할 수 있다.
- 최단 경로를 찾는것과 같이. 최적의 해를 찾는 문제에는 적합하지 않다.
DFS 알고리즘은 다음 상황에서 사용된다.
- 그래프에서 한노드부터 연결된 모든 노드를 탐색해야 할 경우.
- 어떠한 반복되는 노드 간의 사이클을 탐지해야 할 경우,
- 시작 노드에서 목표 노드까지의 경로를 찾아야 할 경우,
- 트리구조 일 경우, 모든 트리를 탐색할 경우.
DFS 알고리즘 의 코드 예시는 다음과 같다.
#include <iostream>
using namespace std;
// 깊이 우선 탐색
// 내가 갈 수 있는 대로 최대한 들어가는 방식.
// 불필요한 경우를 차단하거나 그런건 없다.
// 그래서 경우의 수를 줄일 수 없다.
// 제귀로 들어가는 방법과 스텍으로 들어가는 방법이 있다.
template<typename T>
class Graph
{
public:
struct Node;
struct Edge // 간선 제작
{
Node* Start = NULL;
Node* Target = NULL;
Edge* Next = NULL;
};
struct Node
{
T Data;
int Index = -1;
Node* Next = NULL; // 다음 노드에 대한 포인터
Edge* Edge = NULL; // 다음 간선에 대한 포인터
bool Visited = false; // 방문 여부에 대한 결과
};
private:
Node* Head = NULL;
int Count = 0;
public:
static Edge* CreateEdge(Node* start, Node* target)
{
Edge* edge = new Edge(); // 동적할당.
edge->Start = start;
edge->Target = target;
return edge;
}
static Node* CreateNode(T data)
{
Node* node = new Node();
node->Data = data;
return node;
}
public:
void AddNode(Node* node)
{
Node* nodeList = Head; // Head = 연결리스트에서 머리를 구현한다.
if (nodeList != NULL)
{
while (nodeList->Next != NULL)
{
nodeList = nodeList->Next;
}
nodeList->Next = node; // 새로운 노드가 연결리스트 끝에 위치하게 된다.
}
else
{
Head = node;
}
node->Index = Count++;
}
void AddEdge(Node* node, Edge* edge)
{
if (node->Edge != NULL)
{
Edge* edgeList = node -> Edge;
while (edgeList->Next != NULL)
{
edgeList = edgeList->Next;
}
edgeList->Next = edge;
}
else
{
node->Edge = edge;
}
}
void Print()
{
Node* node = NULL;
Edge* edge = NULL;
if((node = Head) == NULL) // 헤드가 없다면 정보가 없으니까 종료
return;
while (node != NULL)
{
cout << node -> Data << " : ";
if ((edge = node->Edge) == NULL)
{
node = node->Next;
cout << endl;
continue;
}
while (edge != NULL)
{
cout << edge->Target->Data;
edge = edge->Next;
}
cout << endl;
node = node->Next;
}
cout << endl;
}
void DFS(Node* node)
{
cout << node->Data;
node->Visited = true;
Edge* edge = node->Edge;
while (edge != NULL)
{
if(edge->Target != NULL && edge->Target->Visited == false)
DFS(edge->Target);
edge = edge->Next; // 간선이 하나가 아니기 떄문에, 다음 간선도 체크해주는 부분을 만들어주어야 한다.
}
}
};
typedef Graph<char> G;
int main()
{
G graph;
G::Node* n1 = G::CreateNode('A');
G::Node* n2 = G::CreateNode('B');
G::Node* n3 = G::CreateNode('C');
G::Node* n4 = G::CreateNode('D');
G::Node* n5 = G::CreateNode('E');
graph.AddNode(n1);
graph.AddNode(n2);
graph.AddNode(n3);
graph.AddNode(n4);
graph.AddNode(n5);
graph.AddEdge(n1, G::CreateEdge(n1, n2));
graph.AddEdge(n1, G::CreateEdge(n1, n3));
graph.AddEdge(n1, G::CreateEdge(n1, n4));
graph.AddEdge(n1, G::CreateEdge(n1, n5));
graph.AddEdge(n2, G::CreateEdge(n2, n1));
graph.AddEdge(n2, G::CreateEdge(n2, n3));
graph.AddEdge(n2, G::CreateEdge(n2, n5));
graph.AddEdge(n3, G::CreateEdge(n3, n1));
graph.AddEdge(n3, G::CreateEdge(n2, n2));
graph.AddEdge(n4, G::CreateEdge(n4, n1));
graph.AddEdge(n4, G::CreateEdge(n4, n5));
graph.AddEdge(n5, G::CreateEdge(n2, n1));
graph.AddEdge(n5, G::CreateEdge(n2, n2));
graph.AddEdge(n5, G::CreateEdge(n2, n4));
graph.Print();
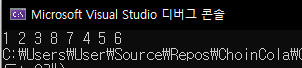
graph.DFS(n1);
return 0;
}
위 코드는 graph 라는 하나의 구조체를 생성한 뒤, 구조체 안에 모든 함수를 구현한 형태이다.