





시스템 소프트웨어
빅데이터 분석을 위한 소프트웨어 스택
| 빅데이터 분석 라이브러리 | Mahout 또는 Spark MLib | 마지막 |
| 병렬처리 | 맵리듀스 프로그램 | 위로 |
| 분산파일시스템 | 하둡분산파일시스템 | 위로 |
| 운영체제 | 리눅스 | 가장 밑 |
데이터 처리는 위에서 밑으로 내려가는 순서로 데이터가 분산된다.
운영체제
윈도우에서 빅데이터 처리가 힘든 이유?
[ 내생각 ] 윈도우에서의 라이브러리는 추가가 힘들기 때문? 오픈소스로 인한 법적분쟁이 따로 일어나지 않기 때문?
[ 윈도우 = 단일 사용자를 위해 만들어진것. ] 다중사용자가 가능하지만, 윈도우는 여러명의 사용자가 동시에 접속할 수 없기 때문, 윈도우는 마우스 전용으로 만들어진 인터페이스 로
마우스 추적이 필요하지만, 리눅스는 터미널로 키보드만으로 접속과 다루기가 가능하다.
GUI체계의 인터페이스가 리눅스에 비해 더 크고 메모리를 더 잡아먹게됨.
운영체제 자체가 가볍지 않고 헤비할 수 있다. 운영체제가 지원해주는 서비스가 많기 때문,
즉. 윈도우와 리눅스의 차이는 사용자의 편의성 차이로 인한 운영체제의 무겁고 가벼운 차이가 있기 때문이다.
[ 요약 ]
운영체제 입장에서 보면 빅데이터 환경에서 보았을 때 윈도우 운영체제는 리눅스에 비해 효율성이 부족하다.
분산파일시스템
분산형 형태의 파일 시스템이 만들어져 있다. 다중처리 시스템으로 큰 데이터를 N분할로 하여 N개 처리속도만큼 처리를 빠르게 할 수 있다.
하둡분산파일시스템을 이용하여 분산된 형태로 파일데이터를 처리할 수 있게 되었다.
병렬처리
맵 리듀스 프로그램 = 하둡보다 더 위에서 데이터를 처리하고 싶을 때 . 하둡분산파일시스템에 데이터를 분산하고 다시 모으고 하는 역활을 함.
빅데이터 분석 라이브러리
병렬 처리를 하면서 데이터의 의미를 도출하고 싶을 때, 처리된 데이터의 의미를 도출할 때 분석 라이브러리를 사용함.
Mahout, Spark MLib 를 이용하여 데이터 안의 가공된 데이터를 이용하여 추가적인 데이터 분석이 가능하다.
시스템 소프트웨어
소프트웨어 = 컴퓨터 시스템이나 주변기기 등의 하드웨어를 작동시켜 원하는 작업 결과를 얻기 위해 실행되는 프로그램
운영체제가 먼저 실행되고 나서 응용프로그램이 실행됨.
- 작업 : 문서작성기, 그림편집기
주변장치를 관리하는 드라이버 프로그램
- 프린터, 인터넷 브라우저
소프트웨어의 종류
시스템 소프트웨어 [ System SosftWare ]
- 응용 소프트웨어가 실행될 때 컴퓨터 하드웨어를 효율적으로 사용하도록 Cpu나 메모리 등의 컴퓨터 자원을 배치하고 관리함.
- 드라이버 프로그램
- 인터페이스 프로그램
- 운영체제
종류 : 운영체제 , 컴파일러 , 데이터베이스 , 유틸리티 소프트웨어
응용 소프트웨어 [ Appllcation ]
종류 : 문서작성기, 그림편집기 그림판같은것
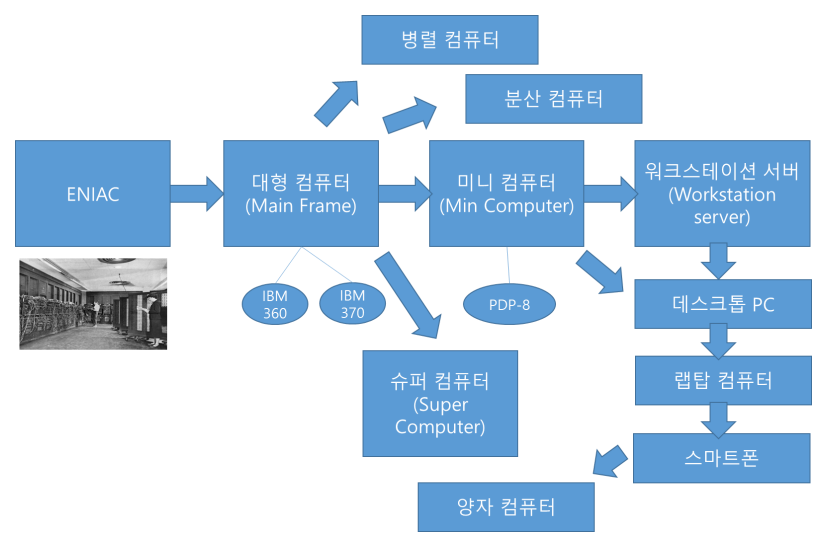
컴퓨터의 발전
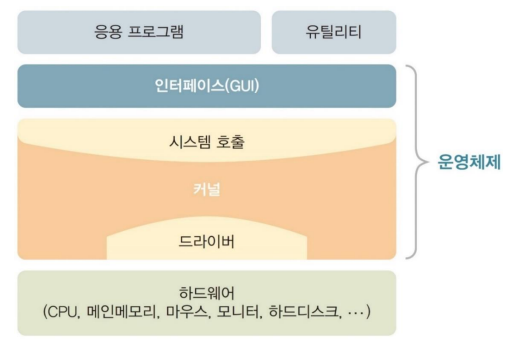
운영체제의 역할
성능향상 - 빅데이터에서 엄청난 향상이 이루어짐
자원관리 - 연결된 형태의 노드를 고려해야 하기에 분산환경으로 메커니즘이 바뀜
자원보호 -
HDD 의 데이터보호방법 = 복사본을 3개 만들어버림
사용자인터페이스제공
메인메모리 관리
프로그램과 프로세스의 차이점
프로그램 = 저장장치에 보관되어있는 실행주체
프로세스 = CPU에 올라와서 실행되고있는 데이터
분산환경에서는 데이터의 사이즈가 메인메모리의 사이즈보다 엄청 큰 것이 발생할 수 있다.
저장장치 관리
노드로 분리하여 데이터를 하드디스크 하나가 아닌 노드별로 여러개의 하드디스크에 데이터를 저장하게됨.
이유 = 하나가 날라가도 다른 노드를 가져와서 데이터를 복원할 수 있기 때문.
시스템 호출 [ System Call ]
운영체제는 인터럽트로 시작해서 인터럽트로 끝나게된다. 즉, 시용자나 응용프로그램이 하드웨어에 직접 접근하지 못하게 막음으로써 컴퓨터 자원을 보오하게 된다. 운영체제에게 어떠한 작업을 지시할때 시스템 콜을 사용한다.
유닉스
1960년대 컴퓨터는 고가였기 때문에 여러명이 동시에 운용할 수 있는 운영체제 개발.
소스코드를 공개하여 많은사람이 개선함. 여기서 리눅스가 파생됨
리눅스
1991년 리눅스 토르발스가 유닉스 호환커널을 만들고 대중에게 공개
특징
다중 플랫폼 [ Multi - Platform] 지원
다양한 하드웨어 장치 지원
네트워크 기능 제공
이식성이 뛰어남
- c언어 기반으로 프로그래밍을 하여 포팅이 용이함
다중사용자 동시에 사용할 수 있는 환경 제공
다중 작업 환경 제공
트리 형태의 계층적 구조로 된 파일 시스템
풍부한 소프트웨어 개발환경 제공
강력한 네트워킹 기능 제공
프로세스의 상태
일괄처리 작업
한 번에 작업을 1개만 처리하는 시스템
시분할 작업
CPU가 1개인 컴퓨터에서 여러 프로세스를 동시에 실행시키는 것처럼 보이기 위해 CPU가 시간을 쪼개어 여러 프로세스에 적당히 배분함.
분산형 시스템에서는 애초에 물리적으로 분리되어 있기 때문에 그냥 분할하여 데이터를 처리하게된다.
메인메모리 관리
폰 노이만 구조를 이용하여 작업을 하게됨.
메모리 = 유일한 작업공간
모든 프로그램은 메모리에 올라와야 실행이 가능하다.
마스터 노드 , 슬레이브 노드 로 구성되어 있으며, 마스터 노드가 데이터를 받아서 균일하거나 균일하지 않거나 의 차이로 데이터를 분류하여 하드웨어 리소스를 재분배하여 데이터를 처리하게 슬레이브 노드에게 시키게됨.

위 이미지에서는 하나의 CPU를 여러개처럼 데이터처리를 하는것을 시분할 시스템을 이용하여 데이터를 처리하였으나,
리눅스 시스템에서는 분산환경으로 인해 도마가 여러개인 효과를 발휘할 수 있다. 즉, 데이터의 처리과정이 다양하게 빠르게 처리된다.
저장장치 관리
[ 이후 수정함 ]
'대학교 코딩공부 > 빅데이터 프로젝트' 카테고리의 다른 글
| 빅데이터 프로젝트 4주차 [ 웹 크롤링 ] (0) | 2022.09.22 |
|---|---|
| 빅데이터 프로젝트 4주차 [ 데이터 분류 ] (0) | 2022.09.22 |
| 빅데이터 프로젝트 4주차 [ 빅데이터 기본 ] (0) | 2022.09.20 |
| 빅데이터 프로젝트 3주차 [ 빅데이터와 머신러닝 ] (0) | 2022.09.13 |
| 빅데이터 프로젝트 2주차 [ 메모리 관리 ] (0) | 2022.09.06 |


















