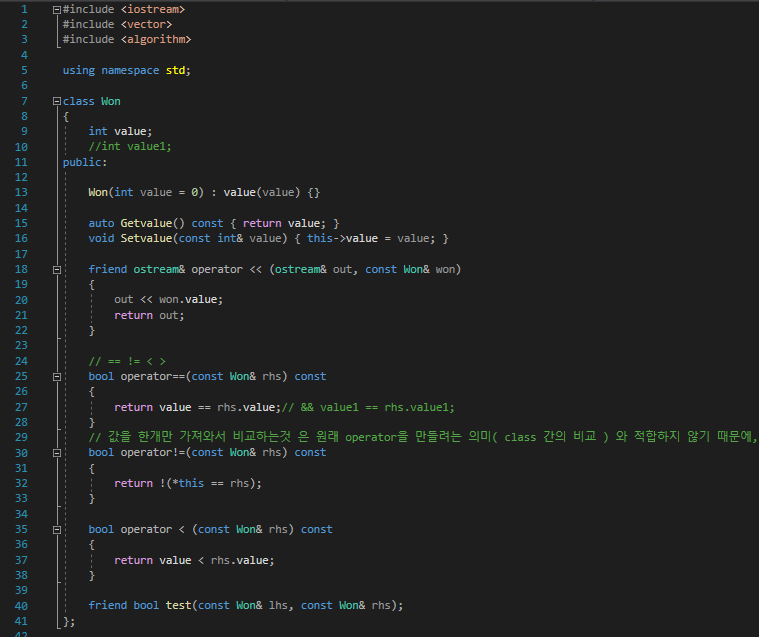
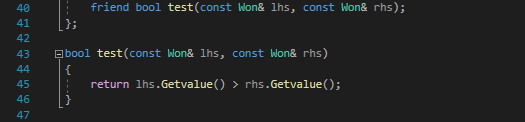
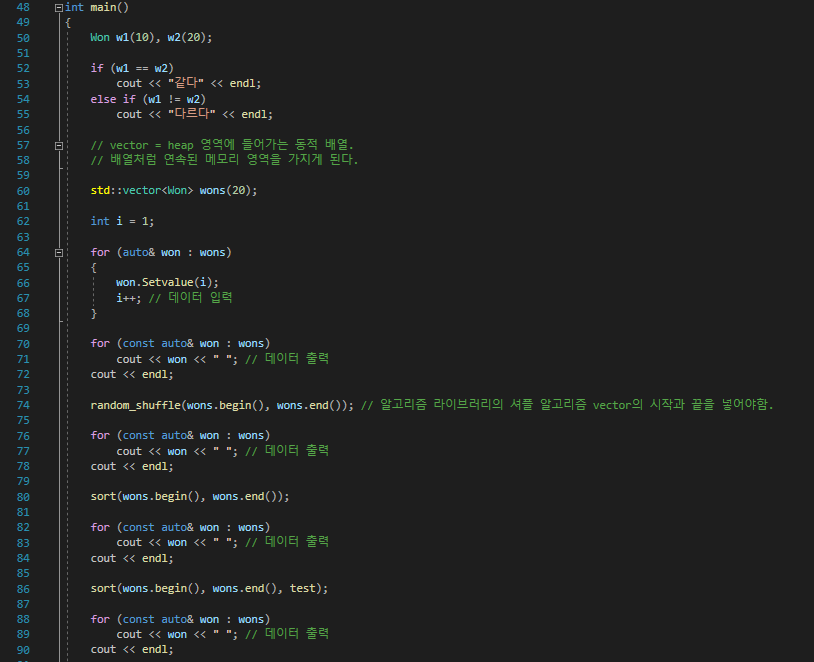
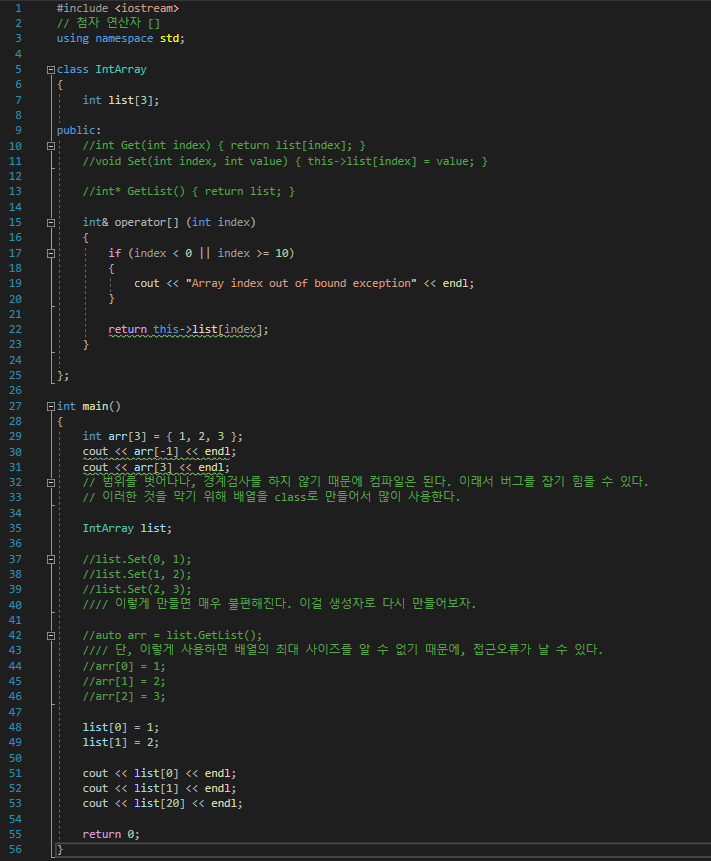
C++에서 class가 생성될 때 기본적으로 만들어지는 것 또한 operator하여, 바꾸어줄 수 있다.
class간의 복사, 이동, 대입, 소멸 을 조정하여 class의 값변경을 더 자유롭고 편하게 지정해주는 방법이다.
#include <iostream>
using namespace std;
class Test
{
int num1;
int num2;
public:
// 클래스가 만들어졌을 때 기본으로 들어가는 것
// 기본
// 복사
// 이동
// 복사 대입
// 이동 대입
// 소멸
// 기본생성자. 로 취급되어 기본생성자는 사라진다.
/*Test(int n1, int n2) : num1(n1), num2(n2)
{}*/
Test(int n1, int n2) : num1(n1), num2(n2)
{}
};
class Fraction
{
int numerator;
int denominator;
public:
Fraction(int num = 0, int den = 0)
: numerator(num), denominator(den)
{
cout << "constructor" << endl;
}
// 복사 연산자
// 이건 임의적으로 동작을 막는 것 이다.
/*explicit*/ Fraction(const Fraction& fraction)
{
cout << "copy constructor" << endl;
}
// 복사 대입 연산자
Fraction& operator = (const Fraction& rhs)
{
cout << "copy assignment operator" << endl;
return *this;
}
};
Fraction CreateFraction()// 이름 있는 객체
{
Fraction temp(5, 2);
return temp;
}
int main()
{
Test t1(1, 2);
Test t2 = t1; // 이럴경우 복사생성자가 된다.
// 아무것도 넣지 않았을 때 디폴트 복사생성자가 들어가서 생성되게 된다.
Fraction frac(3, 5);
Fraction copy1(frac); // 복사 생성자. 복사 초기화
Fraction copy2 = frac; // 복사 생성자.
copy2 = frac; // = operator= 이다. 복사대입 생성자.
int a = 5; // 복사
int b = a; // 복사 대입연산자.
int a(5); // 복사 초기화는 이와 같다.
CreateFraction();
return 0;
}위 방법대로, class 내부에 복사대입, 복사, 등 연산자를 추가하여 원래 추가되는 기본연산자를 바꾸고 더 쉽게 연산을 진행시켜줄 수 있다.
C++에서 RVO와 NRVO라는 개념이 있는데, 이는 함수에서 객체를 반환할 때 복사생성자 호출을 피하여, 성능을 향상시키는 최적화 기법이다. RVO는 객체를 반환하는 경우이고, NRVO는 명시적 이름이 지정된 지역변수를 반환하는 경우에 적용된다.
각 기법은 C++11부터 컴파일러가 자동최적화를 수행해준다.
각 설명은 다음과 같다.
- RVO(Return Value Optimization)
- 함수가 임시객체를 반환하는 경우에 발생한다.
- 컴파일러는 함수 내에서 생성한 이름이 없는 임시객체를 호출한 코드가 있는 변수에 직접 생성하여 복사생성을 하지 않도록 한다.
- 그리하여, 변수를 중복생성하지 않게하여 필요없는 데이터낭비를 피하게 된다.
- NRVO(Named Return Value Optimization)
- 함수에서 명시적으로 이름이 지정된 지역 변수를 반환하는 경우에 발생한다.
- 지역변수에 값을 할당한 다음 반환하는 경우, 컴파일러는 이 변수를 호출한 코드가 있는 변수에 직접 생성하게 된다.
- RVO의 경우와 마찬가지로 복사생성자 호출을 피하는 경우라고 말하면 된다.
- 디버그 시에는 복사하고 대입하는 식으로 연산하지만, 릴리즈 시에는 원본대입 형식으로 최적화해준다.
#include <iostream>
/*
RVO = Retrun Value Optimization
생성할 때 이름없는 객체는 자동최적화. 복사가아니라 원본대입
NRVO = Named Return Value Optimization
이름있는 이름있는 객체를 RVO처럼 해주는것.
최적화 할때 사용하는 방법.
*/
using namespace std;
class Test
{
int value1;
int value2;
public:
static int count;
Test(int value)
:value1(value),
value2(count++) // 생성할 때마다 카운트를 넣어준다.
{
cout << "constructor : " << this->value1 << ", " << this->value2 << endl;
}
Test(const Test& rhs)
:value1(rhs.value1), value2(count++)
{
cout << "copy constructor : " << this->value1 << ", " << this->value2 << endl;
}
~Test()
{
cout << "destructor : " << this->value1 << ", " << this->value2 << endl;
}
};
int Test::count = 1;
Test MakeRVO(int value)
{
return Test(value);
// 임시객체의 생성이 이루어지지 않고 그냥 반환만된다.
}
Test MakeNRVO(int value)
{
Test test(value);
return test;
// 임시객체의 생성이 이루어지고 반환된다. 복사생성자가 호출된다.
}
int main()
{
cout << "---RVO---" << endl;
Test t1 = MakeRVO(1);
cout << "---NRVO---" << endl;
Test t2 = MakeNRVO(1);
// 컴파일러 에서만 이러한 현상이 나타나고, 릴리즈에서는 나타나지 않는다.
return 0;
}위에서 설명한, RVO방식과 NRVO방식에도 operator를 하여, 다양한 방식으로 활용할 수 있다.
생성자를 operator하여, 다양한 방식대로 생성하여 데이터를 기입할 수 있는데, 이 방식을 사용하여 자동형변환을 사용할 수 있다.
#include <iostream>
using namespace std;
class Fraction
{
int numerator;
int denominator;
public:
Fraction(int num, int den)
: numerator(num), denominator(den)
{
cout << "constructor" << endl;
}
Fraction(const Fraction& other)
:numerator(other.numerator), denominator(other.denominator)
{
cout << "copy constructor" << endl;
}
// 생성자를 처음에쓰는것 이 아닌 것을 막아버린다.
explicit Fraction(int a)
: numerator(a), denominator(1)
{
cout << "conversion constructor" << endl;
}
friend std::ostream& operator << (std::ostream& out, const Fraction frac)
{
cout << frac.numerator << " /" << frac.denominator << endl;
return out;
}
};
void PrintFraction(Fraction frac)
{
cout << frac << endl;
}
int main()
{
Fraction frac1(10, 20);
Fraction frac2(frac1);
Fraction frac3(1);
Fraction frac4('A'); // int형으로 자동 형변환이 일어나서 int형으로 들어간다.
Fraction frac5(3.14f); // flaot에서 int로 바뀐다.
PrintFraction(frac1);
PrintFraction(frac2);
PrintFraction(frac3);
PrintFraction(frac4);
PrintFraction(frac5);
//PrintFraction('A');
//PrintFraction(3.14);
//PrintFraction(100);
return 0;
}위 코드에서 Fraction frac4와 frac5는 원래라면, 변수가 들어가면 안되지만, explicit을 뺀다면, int형을 받아서, 값이 들어가게 된다.
C++에서 복사생성을 할 때 얕은복사 와 깊은복사가 있다.
얕은복사는, 값을 가져와서 복사하는 방법으로 복사하게 되는데 여기서 동적생성한 변수를 얕은복사를 하게되면,
값의 복사가 아닌 값의 원본을 가져오는 경우가 생길 수 있다. 그래서 가져온 값을 사용하다가 delete하게 되었을 때 허상포인터 가 생길 수 있어 피치못할 오류에 취약할 수 있다.
그래서 동적생성한 변수나 복사가 아닌 원본값을 가져와서 사용해야할 경우, 다음과 같은 방법을 사용해야 한다.
#include <iostream>
#include <cassert>
using namespace std;
/*
deep copy vs shallow copy
기본 복사 생성자 = 맴버 와 맴버의 복사를 지원하는 얕은복사이다.
이렇게 하면 맴버에 동적할당을 하게 되면, 문제가 생긴다.
그렇기에 내부에서 동적생성을 따로 해주고 복사해야하는 문제가 생긴다.
*/
class Mystring
{
public:
char* data = nullptr;
int length = 0;
Mystring(const char* const src = " ")
{
assert(src);
length = strlen(src) + 1;
data = new char[length];
for (int i = 0; i < length; i++)
data[i] = src[i];
data[length - 1] = '\0';
}
Mystring(const Mystring& other)
{
this->length = other.length;
if (other.data != nullptr)
{
this->data = new char[length];
for (int i = 0; i < this->length; i++)
this->data[i] = other.data[i];
}
else
{
data = nullptr;
}
}
~Mystring()
{
if (data != nullptr)
{
delete[] data;
data = nullptr;
}
}
Mystring& operator =(const Mystring& other)
{
if (this == &other)
{
return *this;
}
if (this->data != nullptr)
{
delete[] this->data;
this->data = nullptr;
cout << "copy assignment operator" << endl;
this->length = other.length;
if (other.data != nullptr)
{
this->data = new char[length];
for (int i = 0; i < this->length; i++)
this->data[i] = other.data[i];
}
else
{
this->data = nullptr;
}
}
return *this;
}
Mystring(Mystring&& other)
{
cout << "move constructor" << endl;
this->data = std::move(other.data);
this->length = std::move(other.length);
other.data = nullptr;
}
Mystring& operator= (Mystring&& other)
{
cout << "Move assignment operator" << endl;
if (this == &other) // prevent self-assignment
return *this;
if (this->data != nullptr)
{
if (other.data != nullptr && this->data != other.data)
{
delete[] this->data;
this->data = nullptr;
this->data = std::move(other.data);
}
}
else
this->data = std::move(other.data);
this->length = std::move(other.length);
other.data = nullptr;
return *this;
}
};
int main()
{
cout << "#################1#################" << endl;
Mystring str("Hello");
cout << (int*)str.data << endl;
cout << str.data << endl << endl;
cout << "#################2#################" << endl;
// copy
{
Mystring copy(str);
copy = str;
cout << (int*)copy.data << endl;
cout << copy.data << endl << endl;
}
cout << "#################3#################" << endl;
if (str.data != nullptr)
{
cout << (int*)str.data << endl;
cout << str.data << endl << endl;
}
else
{
cout << (int*)str.data << endl << endl;
}
cout << "#################4#################" << endl;
{
Mystring copy(std::move(str));
copy = std::move(str);
cout << (int*)copy.data << endl;
cout << copy.data << endl << endl;
}
cout << "#################5#################" << endl;
if (str.data != nullptr)
{
cout << (int*)str.data << endl;
cout << str.data << endl << endl;
}
else
{
cout << (int*)str.data << endl << endl;
}
return 0;
}위 방법대로, operator하여, 생성자 를 정의해주고, 대입연산자와 복사연산자를 따로 만들어주어 깊은복사를 실행할 수 있게 한다.
'서울게임아카데미 교육과정 6개월 C++ ~ DirectX2D' 카테고리의 다른 글
| 33일차. 복습 (0) | 2023.05.17 |
|---|---|
| 32일차. 01.Object_RelationShip, 02.Composition, 03.Aggregation, 04.Assocation, 05.Dependencies (0) | 2023.05.16 |
| 30일차 10.smart_pointer (0) | 2023.05.10 |
| 29일차 04.realational, 05.subcipt_operator, 06.parenthesis_operator, 07.typecaset_operator, 08.new_delete_operator, 09.pointer_operator (0) | 2023.05.05 |
| 28일차 02.input_output_operator 03.Unary_Operator (0) | 2023.05.03 |