
9.6 상속과 관련된 미묘한 문제들
클래스를 확장할 때는 여러 가지 문제가 발생한다. 클래스의 어떤 특성이 유지되고 어떤 특성이 변경되도록 할 것인가? virtual 키워드의 사용 여부는 어떤 영향을 끼치나? 등등...
9.6.1 오버라이딩을 통한 메서드의 특성 변경
대부분 구현 내용을 변경하기 위한 목적으로 메서드를 오버라이딩한다. 하지만 어떤 떄는 구현 내용이 아니라 메서드의 다른 특성을 바꾸고 싶을 때가 있다.
9.6.1.1 리턴 타입 변경
메서드를 오버라이딩할 때는 원본 메서드의 선언, 즉 메서드 프로토타입과 완벽히 같게 오버라이딩을 하는 것이 기본이다. 즉, 구현 내용은 바뀌되 메서드의 프로토타입은 바뀌지 않는다.
그런데 꼭 그래야 하는 것은 아니다. C++에서는 오버라이딩하는 메서드의 리턴 타입을 바꿀 수 있는 경우도 있다. 원본 메서드의 리턴 타입이 어떤 클래스에 대한 포인터나 참조형이라면 오버라이딩하는 메서드의 리턴 타입을 원본 타입 클래스의 파생 클래스에 한하여 바꿀 수 있다. 이런 타입을 공변 리턴 타입(covariant return type) 이라고 한다. 이러한 기능은 베이스 클래스와 파생 클래스가 병렬 계층을 대상으로 작업해야 할 때 편리하게 이용된다. 즉, 어떤 클래스 계층이 완전 별개의 다른 클래스 계층에 작업상 연관된 경우다.
예를 들어 체리 과수원 시뮬레이션 게임이 있다고 하자. 이 게임은 실세계에 있는 두 종류의 객체를 표현하기 위해 두 개의 클래스 계층을 가진다. 첫 번쨰는 체리 열매 계층으로, 베이스 클래스 Cherry와 파생 클래스 BingCherry를 가진다. 이와 비슷하게 CherryTree와 BingCherryTree가 체리 나무 계층을 구성한다. 다음 그림은 이러한 두 클래스 계층을 나타낸다.

이제 CherryTree 클래스가 체리 열매 하나를 수확하기 위한 메서드 pick()을 가졌다고 하자.
Cherry* CherryTree::pick()
{
return new Cherry();
}
파생 클래스 BingCherryTree에서는 위 메서드를 오버라이딩하여 다른 종류의 체리 열매를 수확하게 하고싶다. 체리 열매 종류도 다르지만 체리를 깨끗하게 닦는 작업도 동시에 하려 한다.
이때 BingCherry는 Cherry의 한 종류이기 때문에 다음처럼 메서드 프로토타입을 그대로 두고 구현부만 수정해도 문제가 없다. BingCherry를 Cherry의 포인터로 리턴할 때 자동으로 업캐스팅된다. 이 구현에서는 polish()가 익셉션을 발생시킬 경우를 대비하여 메모리 릭이 발생하지 않도록 unique_ptr을 사용하고 있음을 눈여겨보자.
Cherry* BingCherryTree::pick()
{
auto theCherry = std::make_unique<BingCherry>();
theCherry->polish();
return theCherry.release();
}
이와 같은 구현은 아무런 문제가 없다. 프로그래머의 의도에 따라서 잘 동작할 것이다. 하지만 BingCherryTree는 BingCherry객체를 만들어내는 것이 훨씬 자연스럽다. 그렇게 해야 BingCherryTree의 사용자로 하여금 수확하는 체리의 종류가 BingCherry임을 명확히 할 수 있다.
다음은 리턴 타입을 BingCherry로 고친 pick()메서드이다.
BingCherry* BinghCheryTree::pick()
{
auto theCherry = std::makeunique<BingCherry>();
theCherry->polish();
return theCherry.release();
}메서드를 오버라이딩하면서 리턴 타입 변경이 가능한지 가늠하는 가장 좋은 방법은 기존 코드와 문제없이 작동 가능할지 생각해보는 것이다. 이것을 리스코프 치환 원칙(Liskov substitution principle[LSP])이라고 한다.
전 예제에서 리턴타입을 바꾸었지만, 기존 코드와 작동하는 데는 아무런 문제가 없다. BingCherry*는 Cherry의 한 종류로서 Cherry*와 호환이 되기 때문에 CherryTree의 pick()을 사용한 코드와 컴피일과 런타임 작동 모두 정상적으로 된다.'
하지만 오버라이딩하는 메서드의 리턴 타입을 void*와 같은 전혀 관계없는 타입으로 바꿀 수 는 없다. 다음 코드는 컴파일되지 않는다.
void* BingCherryTree::pick() // 컴파일 에러!
{
auto theCherry = std::make_unique<BingCherry>();
theCherry->polish();
return theCherry.release();
}위 코드는 리턴값이 공변 타입이 아니라는 컴파일 에러를 발생시킨다. 이때 에러 메시지는
'BingCherryTree::pick':overriding virtual function return type differs and is not covariant from 'CherryTree::pick'과 비슷하다.
9.6.1.2 파라미터 변경
부모 클래스의 virtual메서드를 오버라이딩 하기 위해 파생 클래스에서 같은 함수명에 같은 리턴타입의 메서드를 선언하더라도 메서드 파라미터가 다르면 오버라이딩 되지 않는다. 예를 들어 앞서 보았던 Super와 Sub클래스의 예에서 someMethod()를 Sub클래스에서 다음처럼 새로운 인자 목록으로 선언하는 경우를 보자.
class Super
{
public:
Super();
virtual void someMethod();
};
class Sub : public Super
{
public:
Sub();
virtual void someMethod(int i); // 컴파일은 되지만 오버라이딩은 되지 않는다.
virtual void someOtherMethod();
};
이 메서드의 구현부 정의는 다음과 같다.
void Sub::someMethod(int i)
{
cout << "THis is Sub's version of someMethod with argument " << i <<
". " << endl;
}
이 예제에는 컴파일에는 문제가 없지만, someMethod()에 대한 오버라이딩은 발생하지 않는다. 왜냐하면 인자 목록이 다르기 때문에, Sub에서 새로운 메서드를 선언한 것이 되어버리기 때문이다. 만약, int를 받는 someMethod()가 Sub에서만 동작하길 원하는 거라면 의도한 대로 작동한다.
사실 C++표준에서는 Sub로 접근되면 Sub에서 재정의한 Super의 메서드가 숨겨지도록 하고 있다. 예를 들어 다음과 같이 인자가 없는 베이스 클래스의 someMethod() 메서드를 호출하려 하면 컴파일 에러가 발생한다.
Sub myLSub;
mySub.someMethod(); // 버그! 원래 메서드가 숨겨졌기 때문에 컴파일이 안 된다!의도하는 동작이 베이스 클래스의 someMethod()를 오버라이딩하여 원본 대신 호출하게 하는 것이라면, someMethod(int)를 Sub에서 선언할 때 명시적으로 override지정자를 표기해야 한다. 그렇게 하면 컴파일러가 someMethod(int)를 만났을 때 베이스 클래스의 메서드와 파라미터 타입이 달라서 오버라이딩할 메서드가 없다는 오류 메시지를 출력한다.
이러한 작동 방식은 상황에 따라서 적합할 수도 있고 의도하지 않은 것일 수도 있다. 만약 의도하지 않은 경우라면 using키워드를 이용해서 베이스 클래스의 메서드를 그대로 이용할 수 있도록 명시적으로 지정할 수 있다. using키워드로 베이스 클래스의 메서드를 지정하면 베이스 클래스의 메서드 프로토타입과 구현부 정의를 그대로 이용하게 된다.
class Super
{
public:
Super();
virtual void someMethod();
};
class Sub : public Super
{
public:
Sub();
using Super::someMethod; // 명시적으로 부모 클래스의 메서드를 상속받음
virtual void someMethod(itn i); // 새로운 버전의 someMethod 추가
virtual void someOtherMethod();
};보통은 같은 이름이면서 파라미터가 다른 메서드가 베이스 클래스와 파생 클래스에 각기 존재해야 하는 경우는 많지 않다.
override키워드
위와 같은 작동방식 때문에, 어떤 경우에는 오버라이딩하려는 의도임에도 실수로 새로운 메서드를 추가하게 되어버릴 수도 있다. 다음 코드에서는 Sub에서 Super의 someMethod()를 적합하게 오버라이딩하고 있다.
class Super
{
public:
Super();
virtual void someMethod(double d);
};
class Sub : public Super
{
public:
Sub();
virtual void someMethod(double d);
};
적합하게 오버라이딩되었기 때문에 다음처럼 Sub객체를 Super의 참조로 접근하더라도 오버라이딩된 메서드가 호출된다.
Sub mySub;
Super& ref = mySub;
ref.someMEthod(1); // Sub의 someMethod()가 호출됨
여기서는 Sub클래스에서 오버라이딩한 someMethod()가 올바르게 호출된다. 이제 아래 코드처럼 double타입 인자 대신 int타입 인자를 사용하는 soemMethod()를 오버라이딩 하려 했다고 해보자.
class Sub : public Super
{
public:
Sub();
virtual void someMethod(int i);
};
이전 절에서 보았듯이 인자가 다르기 때문에 int타입 someMethod()는 부모 클래스의 double타입 메서드를 오버라이딩하는 것이 아니라 그냥 새로운 virtual메서드를 추가하는 것에 지나지 않는다.
이 때문에 다음처럼 Sub객체를 Super의 참조로 접근할 떄 Sub의 someMethod()가 아니라 Super의 someMethod()가 호출된다.
Sub mySub;
Super& ref = mySub;
ref.someMethod(1.1); // SUper의 someMethod()가 호출됨
이런 유형의 문제는 Super클래스를 수정하면서, Sub클래스도 업데이트해야 한다는 사실을 잊어버렸을 떄 발생할 수 있다. 예를 들어 처음에는 Suepr의 someMethod()를 int타입 인자를 받도록 구현했었지만, 나중에 다른 필요에 의해 double타입 인자로 수정했다고 하자, 그런데 파생 클래스의 soemMethod()는 당연하지만 이전 버전의 Super에 맞추어져 있어서 모두 int타입 인자를 받고 있다.
이 부분도 Super에서 수정한 대로 double로 바꾸어야 하지만 미처 거기까지 생각하지 못했다고 하자. 이 때문에 원래는 베이스 클래스의 메서드를 오버라이딩하던 파생 클래스의 메서드들이 졸지에 파생 클래스만의 새로운 메서드가 되어버린다.
다음처럼 override 키워드를 사용하면 이런 문제를 방지할 수 있다.
class Sub : public Super
{
public:
SUb();
virtual void someMethod(int i) override;
};
이처럼 오버라이딩할 메서드에 override키워드를 사용하면, 해당 메서드가 오버라이딩 이 아닌 신규 메서드가 될 수 밖에 없을 때 컴파일 에러가 발생한다. 위 코드의 경우 부모에 정의된 someMethod()에는 int타입 인자를 받는 메서드가 없으므로 오버라이딩 할 수 없다. 이 때 override키워드를 사용했기 때문에 컴파일러가 에러를 발생시켜 의도와 다른 상황이 발생했음을 알려 준다.
override키워드는 베이스 클래스에서 메서드 이름은 변경해버렸을 때 파생클래스의 메서드가 단독 베서드가 되어버리는 문제도 방지해준다.
이베이스 클레스의 메서드를 오버라이딩할 때는 항상 override 키워드를 사용하도록 한다.
9.6.2 생성자의 상속
앞서 소개했던 using키워드는 베이스 클래스의 메서드 사용을 명시적으로 선언할 수 있게 해주었다. using키워드는 생성자에도 적용할 수 있다. 다음과 같이 Super와 Sub클래스가 정의되어 있다고 하자.
class Super
{
public:
Super(const std::string& str);
};
class SUb : public Super
{
public:
Sub(int i);
};
당연하게도 Super의 객체를 생성하려면 string타입 생성자만 이용해야 한다. 반면 Sub의 객체를 생성하려면 int타입 생성자만 이용해야 한다. Sub객체 생성을 위해 Super에 정의된 string타입 생성자를 이용할 수는 없다.
Super super("Hello"); // 정상, Super의 string타입 생성자 호출
Sub sub1(1); // 정상, Sub의 int타입 생성자 호출
Sub sub2("Hello"); // 컴파일 에러! Sub는 Super의 생성자로 생성될 수 없음
만약 Sub의 객체 생성에 Super의 string타입 생성자를 이용하고 싶다면 다음처럼 using키워드를 이용해서 명시적으로 Super의 생성자 상속을 선언할 수 있다.
class Sub : public Super
{
public:
using Super::Super;'
Sub(int i);
};
이렇게 하면 Super의 생성자가 추가되어 Sub객체 생성 방법이 다음처럼 두 가지로 늘어난다.
Sub sub1(1); // 정상, Sub의 int타입 생성자 호출
Sub sub2("Hello"); // 정상, Super로 부터 상속받은 string타입 생성자 호출
상속받는 생성자에 대해서도 일반 메서드를 오버라이딩하듯이 파생 클래스에 오버라이딩할 수 있다. 예를 들어 다음 코드에서는 Sub가 Super의 생성자를 using키워드를 이용해서 상속받고 있다. 그런데, Sub에서 float타입 생성자를 재정의하고 있기 때문에 Super에 정의된 float타입 생성자는 오버라이딩 된다.
class Super
{
public:
Super(const std::string& str);
Super(float f);
};
class Sub : public Super
{
public:
using Super::Super;
Sub(float f); // Super에서 상속받은 float 타입 생성자를 오버라이딩
};
생성자 상속과 생성자 오버라이딩으로 인해 Sub의 생성은 다음처럼 될 수 있다.
Sub sub1("Hello"); // 정상, Super에서 상속받은 string타입 생성자 호출
Sub sub2(1.23); // 정상, Sub에서 오버라이딩한 float타입 생성자 호출
using 구문으로 생성자를 상속받을 때는 몇 가지 제약 사항이 있다.
첫 번째 제약 사항은 생성자를 선택적으로 상속받을 수 없다는 점이다. 베이스 클래스의 생성자들을 한꺼번에 상속 받아야 한다.
두 번째 제약 사항은 다중 상속에 관련된 것으로, 다중 상속받은 베이스 클래스 들 중 같은 파라미터 목록의 생성자를 가진 경우가 있다면 생성자를 상속받을 수 없다.
왜냐하면, 생성자를 호출할 때 어느쪽 부모의 것을 호출해야 할지 알 수 없기 때문이다. 이러한 모호성을 해소하기 위해 파생 클래스에서 충돌하는 생성자를 명시적으로 오버라이딩해야 한다. 예를 들어 다음 코드에서는 Sub에서 Super1과 Super2의 모든 생성자를 상속받으려 하고 있는데, float타입 생성자가 Super1과 Super2에서 중복되기 떄문에 컴파일 에러가 발생한다.
class Super1
{
public:
Super1(float f);
};
class Super2
{
public:
Super2(const std::string& str);
Super2(float f);
};
class Sub : public Super1, public Super2
{
public:
using Super1::Super1;
using Super2::Super2;
Sub(char c);
};
Sub의 첫 번쨰 using구문에서는 SUper1의 생성자를 상속받는다. 즉, Sub에서 다음 생성자를 얻게된다.
Sub(float f); // SUper1에서 상속받은 생성자
두 번째 using구문에서는 Super2의 생성자를 상속받으려 시도한다. 하지만 이 때는 Sub가 이미 가지고있는 Sub(float f)생성자를 다시 얻으려 하기 때문에 컴파일 에러가 발생한다. 이 문제는 다음 코드처럼 충돌되는 생성자를 Sub에서 명시적으로 재정의하여 해결할 수 있다.
class Sub : public Super1, public Super2
{
public:
uisng Super1::Super1;
using Super2::Super2;
Sub(char c);
Sub(float f);
};
Sub클래스에서 float타입 인자를 받는 생성자를 명시적으로 선언함으로써 모호성을 해소하고있다. 원한다면 float타입 생성자에서 생성자 초기화 리스트를 통해, Super1과 Super2의 생성자를 호출할 수도 있다.
Sub::Sub(flaot f) : Super1(f), Suepr2(f) {}
상속받은 생성자를 이용할 때는 모든 멤버 변수가 정상적으로 초기화되는지 잘 따져보아야 한다. 예를 들어 Super와 Sub 클래스가 다음처럼 정의되어 있다면 mInt가 초기화되지 않는 경우가 발생한다.
class Super
{
public:
Super(const std::string& str) : mStr(str) {}
private:
std::string mStr;
};
class Sub : public Super
{
public:
using Super::Super;
Sub(int i) : Super(""), mInt(i) {}
private:
int mInt;
};
Sub 객체를 생성할 때는 다음과 같이 할 수 있다.
Sub s1(2);
위 코드는 생성자 Sub(int i)를 호출한다. Sub(int i)에서는 mInt 데이터 멤버를 초기화하고 공백 문자를 인자로하여 Super의 생성자를 호출하고 Super의 mStr데이터 멤버를 초기화 한다.
Super의 생성자를 Sub클래스에서 상속받았기 때문에 다음처럼 Sub객체를 생성할 수도 있다.
Sub s2("Hello World");
위 코드는 Sub에서 상속받은 Super의 생성자를 호출한다. 그런데, Super의 생성자는 Super클래스에 정의된 mStr데이터 멤버만 초기화하고 Sub클래스의 데이터 멤버인 mInt는 초기화하지 않는다. 이렇게 객체 생성 시에 초기화하지 않은 데이터 멤버는 나중에 문제의 원인이 된다.
전에 설명한 클래스 내 멤버 초기화(in-class member initialization)를 통해 이 문제에 대응할 수 있다.
밑 코드는 mInt를 클래스 안에서 멤버 선언과 동시에 0으로 초기화 하고 있다. 클래스 내 멤버 초기화를 하더라도 여전이 Sub(int i )에서 인자 i를 통한 초기화를 이용할 수 있다.
class Sub : publc Super
{
public:
using Super::Super;
Sub(int i) : Super(""), mInt(i) {}
private:
int mInt = 0;
};9.6.3 메서드 오버라이딩의 특수한 경우들
이 절에서는 특별히 주의를 기울여야 하는 메서드 오버라이딩 상황을 살펴본다.
9.6.3.1 베이스 클래스의 메서드가 static인 경우
C++에서는 static메서드를 오버라이딩 할 수 없다. 보통은 이 사실만 기억하고 있으면 되지만, 그것이 어떤 영향을 미치는지 살펴볼 필요는 있다.
첫 번째로 메서드가 static이면서 동시에 virtual일 수는 없다. 만약 파생 클래스에서 베이스 클래스에 있는 static메서드와 같은 이름의 메서드를 정의하면 두 개의 서로 다른 메서드가 만들어진다.
다음 코드는 두 클래스에서 beStatic()메서드를 동시에 static으로 선언하고 있는데 이 두 메서드는 서로 독립적이다.
class SUperStatic
{
public:
static void beStatic() {
cout << "SuperStatic being static." << endl; }
};
class SubStatic : public SuperStatic
{
public:
Static void beStatic() {
cout << "SubStatic keepin' it static." << endl; }
};
static메서드는 정의된 클래스에 종속되기 때문에 같은 이름의 메서드이더라도 호출할 때 참조된 클래스에 맞추어 그에 속한 메서드가 실행된다. 즉, 다음 코드를 실행하면
SuperStatic::beStatic();
SubStatic::beStatic();
다음과 같이 출력된다.
SuperStatic being static.
SubStatic keepin' it static.
스코프 지정 연산자로 클래스를 지정하여 static메서드를 호출할 떄는 모든 것이 명확하다. 하지만 객체를 이용할 때는 기대한 대로 동작하지 않는다. static메서드는 this포인터가 있을 수 없으므로 객체를 이용해서 호출하더라도 객체에 연관되는 부분이 없다. 그래서 클래스 이름을 통해 호출(classname::method())하는 것과 같다. 이전 예제에서 객체를 이용하도록 바꾸면 다음과 같다.
SubStatic mySubStatic;
SuperStatic& ref = mySUbstatic;
mySubstatic.beStatic();
ref.beStatic();
첫 번째 beStatic()호출은 SubStatic객체에 Substatic탕비으로 참조하므로 의심할 여지 없이 SubStatic의 메서드가 호출된다. 두 번째 호출은 예상과 다르다. SubStatic의 객체이지만 현재 참조되고 있는 타입인 SuperStatic의 beStatic()이 호출된다.
C++에서는 객체가 무엇이든 관계없이 접근하는 타입에 맞추어 호출할 static메서드를 결정한다. 즉, 컴파일 타임에 참조하는 타입의 종류만 영향을 미치고 실제 객체가 무엇인지는 상관이 없다.
코드의 실행 결과는 다음과 같다.
SubStatic keepin' it static.
SuperStatic being static.
static 메서드는 그 메서드가 정의된 클래스에 의해서만 스코프가 지정되고 메서드가 호출되는 객체의 종류에는 영향을 받지 않는다. 클래스 안에서 static메서드를 호출할 때는 일반적인 스코프가 적용된다. 문법상 객체를 통해 실제 객체의 타입과는 관계없이 그 객체를 참조하고 있는 타입만 호출할 메서드를 결정한다.
9.6.3.2 베이스 클래스의 메서드가 오버로딩 된 메서드인 경우
특정 이름과 파라미터로 메서드를 오버라이딩하면 파라미터와 관계없이 같은 이름을 가지는 베이스 클래스의 모든 메서드가 컴파일러에 의해 숨겨지게 된다. 특정 프로토타입의 메서드를 오버라이딩했다는 것은 파라미터 형태가 다르더라도 같은 이름의 다른 메서드들도 모두 오버라이딩하겠다는 의도가 있다고 볼 수 있다.
이 때문에 명시적으로 오버라이딩 하지 못한 메서드의 이용을 오류로 취급하여 잠재적인 실수를 방지한다. 이러한 방식은 다분히 상식적이다. 일반적으로 볼 때 같은 이름을 가진 여러 메서드 중 일부만 오버라이딩하고 나머지는 그냥 둘 이유가 없다.
이 문제를 살펴보기 위해 다음과 같이 베이스 클래스의 같은 이름의 메서드 들 중 일부만 오버라이딩 한 예를 보자.
class Super
{
public:
virtual void overload() { cout << "Super's overload()" << endl; }
virtual void overload(int i) {
cout << "Super's overload(int i)" << endl; }
};
class Sub : public Super
{
public:
virtual void overload() { cout << "Sub's overload()" << endl; }
};
만약 다음처럼 Sub객체를 통해 overload(int i) 메서드를 호출하려 하면 베이스 클래스에 존재하더라도 명시적으로 오버라이딩 하지 않았기 떄문에 없는것으로 취급되어 컴파일 에러가 발생한다.
mySub.overload(2); // 버그! 해당 메서드를 찾을 수 없음
그런데 Sub객체에서 위 메서드를 호출할 방법은 있다. 포인터나 참조형을 통해 Super객체에 접근하면 된다.
Sub mySub;
Super* ptr = &mySub;
ptr->overload(7);
파생 클래스에서 오버라이딩되지 않은 부모 클래스의 오버로딩된(파라미터 타입이 다른) 동일 메서드들이 숨겨지는 것은 해당 클래스 계층엠나 적용된다. 즉, 명시적으로 해당 클래스 타입으로 접근될 때만 베이스 클래스의 메서드들이 감춰지고, 간단하게 베이스 클래스 타입 캐스팅만 하면 다시 이용할 수 있게 된다.
오버라이딩 구현을 일부에만 적용하고 나머지는 베이스 클래스것을 그대로 사용하고 싶다면 uisng키워드를 이용한다. 다음은 using키워드를 이용해서 한 종류의 overload()함수만 오버라이딩하고 나머지는 Super의 것을 명시적으로 이용하도록 한 예 이다.
class Super
{
public:
virtual void overload() { cout << "Super's overload()" << endl; }
virtual void overload() { cout << "Super's overload(int i)" << endl; }
};
class Sub : public Super
{
public:
using SUper::overload;
virtual void overload() override { cout << "Sub's overlaod()" << endl; }
};
using 키워드는 같은 이름이기만 하면 모두 사용하도록 선언하기 때문에 의도되지 않은 위험이 있을 수 있다. 예를 들어 Super클래스에 새로운 overload()메서드가 추가되어도 아무런 에러메시지가 발생하지 않기 때문에 Sub을 구현한 입장에서 새로운 베이스 클래스의 메서드를 검토해야 한다는 사실을 알지 못할 수 있다. using키워드를 사용할 때는 베이스 클래스의 오버라이딩하는 메서드 계열의 현재 메서드 뿐만 아니라 미래에 추가될 메서드까지 모두 이용하겠다는 선언임을 주의해야 한다.
찾기 어려운 버그를 만들지 않으려면 메서드를 오버라이딩할 때 서로 다른 파라미터로 정의된 해당 메서드의 모든 버전을 오버라이딩하거나 using 키워드를 이용해서 명시적으로 베이스클래스의 메서드 이용을 선언하는 것이 바람직하다. 단, using키워드를 사용할 떄는 앞서 설명한 위험 요소를 잘 고려해야 한다.
9.6.3.3 private또는 protected로 선언된 베이스 클래스의 메서드
private 또는 protected로 접근 권한이 제한된 베이스 클래스의 메서드도 오버라이딩할 수 있다. 접근자는 단지 누가 해당 메서드를 호출할 수 있는지 제한할 뿐으로 오버라이딩과는 관계가 없다. 즉, private로 선언된 부모 클래스의 메서드를 파생 클래스에서 호출할 수는 없지만 오버라이딩은 할 수 있다. 사실 private또는 protected메서드의 오버라이딩은 객체지향 언어에서 아주 흔한 패턴이다.
이 패턴은 파생 클래스가 파생 클래스만의 특징적인 부분을 베이스 클래스에서 반영할 수 있게 해준다. Java와 C#은 public과 protected메서드만 오버라이딩할 수 있으며, private 메서드는 오버라이딩할 수 없다.
예를 들어 다음의 자동차 시뮬레이션 클래스를 보자. 이 시뮬레이션에서는 자동차의 주행 가능 거리를
남아있는 연료(Gallons left)와 연비(Miles Perr Gallon)를 기반으로 예측해준다.
class MilesEstimator
{
public:
virtual int getMilesLeft() const {
return getMilesPerGallon() * getgallonsLeft();
}
virtual void setGallonsLeft(int inValue) { mGallonsLeft = inValue; }
virtual int getGallonsLeft() { return mGallonsLeft; }
private:
int mGallonsLeft;
virtual int getMilesPerGallon() { return 20; }
};getMilesLeft()메서드는 나머지 두 메서드 getMilesPerGallon()과 getGallonsLeft() 에 의존하여 계산을 한다. 다음 코드는 위에서 정의한 MilesEstimator클래스를 이용해서 2갤런의 연료로 얼마나 멀리 갈 수 있는지 출력해준다.
MilesEstimator myMilesEstimator;
myMilesEstimator.setGallonsLeft(2);
cout << "I can go " << myMilesestimator.getMilesLeft() << ' more miles. " << endl;
위 코드의 실행 결과는 다음과 같다.
I can go 40 more miles.
이 시뮬레이터에 연비가 더 좋은 다른 자동차를 추가했다고 하자. 기존의 MilesEstimator클래스는 1갤런당 20마일의 연비를 가정하고 있다. 이 연비는 별도의 메서드에서 결정되고 있기 때문에, 다음처럼 파생 클래스에서 오버라이딩하여 연비를 바꿀 수 있다.
class EfficientCarMilesEstimator : public MilesEstimator
{
private:
virtual int getMilesPerGallon() const override { return 35; }
};
public메서드는 그대로 둔 채 private메서드를 오버라이딩하여 행동 방식이 다른 새로운 클래스를 만들었다. 베이스 클래스에 정의된 getMilesLeft()메서드는 자동으로 오버라이딩된 private getMilesPerGallon()메서드를 호출한다. 새로운 클래스는 다음처럼 이용될 수 있다.
EfficientCarMilesEstimator myEstimator;
myEstimator.setGallonsLeft(2);
cout << "I can go " << myEstimator.getMilesLeft() << " more miles." << endl;
위 코드는 오버라이딩된 기능을 반영하여 다음과 같이 다른 실행 결과를 출력한다.
I can go 70 more miles.
전반적인 변경이 필요하지 않고 특정 속성만 바꾸면 될 때는 private나 protected메서드를 오버라이딩하는 것이 좋은 방법이다.
9.6.3.4 베이스 클래스의 메서드가 디폴트 인자값을 가진 경우
파생 클래스와 베이스 클래스는 각자 서로 다른 디폴트 인자값을 가질 수 있다. 하지만 어느 디폴트 인자가 이용될 지는 (static 메서드와 비슷하게) 실제 이요된 객체와 관계없이, 호출할 때 어느 클래스 타입을 이용했느냐에 의해 결정된다. 다음은 파생 클래스에서 베이스 클래스와 다른 디폴트 인자값을 갖게 메서드를 오버라이딩 하는 예다.
class Super
{
public:
virtual void go(int i = 2) {
cout << "Super's go with i=" << i << endl; }
};
class Sub : public Super
{
public:
virtual void go(int i = 7) {
cout << "Sub's go with i=" << i << endl; }
};
만약, 메서드 go()가 Sub객체에서 호출되면 Sub의 go()가 실행되고 디폴트 인자값 7이 적용된다. go()가 Super객체에서 실행되면 Super의 go()가 실행되고 디폴트 인자값 2가 적용된다. 하지만 조금 이상하게도, Sub객체를 Super타입 포인터 또는 참조로 접근하여 go()를 호출하면 go()의 바디는 Sub의 것이 실행되지만 디폴트 인자는 Super에서 정의한 2가 적용된다.
Super mySuper;
Sub mySub;
Super& mySuperReferenceToSub = mySub;
mySuper.go();
mySub.go();
mySuperReferenceToSub.go();
위 코드의 실행 결과는 다음과 같다.
Super's go with i= 2
Sub's go with i= 7
Sub's go with i= 2
이러한 결과가 나오는 이유는 C++에서 디폴트 인자값을 결정할 때 실제 이용된 객체는 보지 않고 컴파일 타임에 코드에서 표현된 타입만 보기 때문이다. 이 떄문에 디폴트 인자값은 C++에서 상속되지 않는다. 만약 Sub에서 디폴트 인자값 없이 go()메서드를 정의하면 디폴트 인자값을 가진 Super의 메서드가 오버라이딩되지 않고 인자가 하나 이상 있는 새로운 메서드가 오버라이딩 된다.
디폴트 인자값이 있는 메서드를 오버라이딩할 떄는 항상 같은 값으로 디폴트 인자값을 정의해주는 것이 바람직하다. 그리고 디폴트 인자값은 상수 심벌을 별도로 정의해서 파생 클래스에서 이용할 수 있게 하는 것이 좋다.
9.6.3.5 베이스 클래스와 접근자를 달리 해야 할 때
오버라이딩하는 메서드의 접근 권한을 높이거나 낮출 수도 있다. 이러한 변경이 필요한 경우는 상당히 드물지만 몇 가지 상황이 존재하기는 한다.
접근 권한을 강화하고 싶을 때는 두 가지 방법이 있다.
첫 번째 방법은 베이스 클래스 전체에 대한 접근자를 변경하는 것이다. 이 방법은 나중에 설명한다.
두 번째 방법은 아래 예제처럼 파생 클래스에서 해당 메서드의 접근자만 바꾸는 것이다.
class Gregarious
{
public:
virtual void talk() override {
cout << "Gregarius sys hi!" << endl; }
};
class Shy : public Gregarious
{
protected:
virtual void talk() override {
cout << "Shy reluctantly says hello." << endl; }
};
Shy클래스는 Gregarius클래스의 talk()메서드를 protected로 변경하여 재정의하고 있다. 이 때문에 Shy객체에 대해 talk()메서드를 호출하는 외부 코드는 컴파일 에러가 발생한다.
myShy.talk(); // 에러! protected 메서드에 접근
하지만 이 메서드가 완전히 protected로 바뀐건 아니다. 포인터나 참조를 통해 상위클래스의 타입으로 접근하면 여전히 호출할 수 있다.
Shy myShy;
Gregarious& ref = myShy;
ref.talk();
위 코드의 실행 결과는 다음과 같다.
Shy reluctantly says hello.
위 결과는 메서드가 잘 오버라이딩되었다는 것을 보여줌과 동시에 베이스 클래스에서 public으로 선언한 메서드를 완전하게 protected로 막을 수 없다는 것도 보여준다.
부모 클래스의 public메서드 접근을 파생 클래스에서 막을 수 있도록 할 적법한 방법도 없고 그렇게 해야할 이유도 없다.
위 예제는 파생 클래스에서 다른 메시지를 출력하기 위한 목적으로 메서드를 재정의하고 있다. 만약 구현부는 바꾸고 싶지 않고 메서드의 접근 권한만 바꾸고 싶다면 파생 클래스에서 using 구문을 이용하면서 새로운 접근 권한으로 선언한다.
파생 클래스에서 접근 권한을 낮추는 방법은 훨씬 쉬울 뿐만 아니라, 활용성 측면에서도 좀 더 자연스럽다. 가장 간단한 방법은 다음처럼 베이스 클래스의 protected메서드를 파생 클래스의 public 메서드에서 중계하는 것이다.
class Secret
{
protected:
virtual void dontTell() { cout << "I'll never tell." << endl; }
};
class Blabber : public Secret
{
public:
virtual void tell() { dontTell(); }
};
사용자는 Blabber 객체의 public tell()메서드를 경유하여 Secret클래스의 protected메서드를 호출할 수 있다. 물론 이러한 방법이 dontTell()메서드의 접근 권한을 바꾼 것은 아니지만 외부에서 접근할 수 있도록 public한 인터페이스를 제공하는것만은 분명하다.
명시적으로 dontTell()메서드의 접근자를 바꾸어 오버라이딩함으로써 Blabber파생 클래스에서 public접근이 가능하게 할 수도 있다. 이러한 상황은 앞의 권한 강화 경우에 비해 포인터 참조를 통해 베이스 클래스 타입으로 접근할 때 어떤 일이 벌어질지 상식적으로 예측하기 쉽다.
예를 들어 다음과 같이 Blabber에서 dontTell()메서드를 public으로 만들었다면,
class Secret
{
protected:
virtual void dontTell() { cout << "I'll nevet tell." << endl; }
};
class Blabber : public Secret
{
public:
virtual void dontTell() { cout << "I'll tell all!" << endl; }
};
dontTell()메서드를 Blabber객체에서 호출할 떄 아무런 접근 제한이 발생하지 않는다.
myBlabber.dontTell(); // "I'll tell all!" 출력
하지만 포인터나 참조를 통해 베이스 클래스 타입으로 dontTell()메서드를 호출하려 하면 protected메서드에 대한 접근으로 컴파일 에러가 발생한다.
Blabber myBlabber;
Secvret& ref = myBlabber;
Secret* ptr = &myBlabber;
rev.dontTell(); // 에러! protected메서드에 대한 접근
ptr->dontTell(); // 에러! protected메서드에 대한 접근
오버라이딩을 통한 접근 권한 변경이 실용적으로 활용되는 경우는 파생 클래스에서 베이스 클래스의 protected메서드에 대해 권한을 낮추는경우이다.
9.6.4 파생 클래스에서의 복제 생성자와 대입 연산자
8장에서 살펴보았듯, 클래스 안에서 동적 메모리 할당을 사용할 때 복제 생성자와 대입 생성자를 정의하면 편리하게 이용할 수 있다. 복제 생성자와 대입 연산자가 사용된 클래스의 파생 클래스를 만들 때는 주의해야 할 점이 있다.
만약 파생클래스에 포인터 같은 특별한 데이터가 없어서 복제 생성자나 대입 연산자에서 해줘야 할 일이 없다면 베이스 클래스가 복제 생성자나 대입 연산자를 가졌더라도 파생 클래스에서 그것을 다시 구현할 필요는 없다. 파생 클래스에서 복제 생성자나 대입 연산자를 구현하지 않더라도 컴파일러가 디폴트 복제 생성자나 대입 연산자를 만들어주어서
파생 클래스의 멤버가 복제 또는 대입될 수 있도록 해준다. 이 때 베이스 클래스의 멤버에 대해서는 베이스 클래스의 복제 생성자나 대입 연산자가 적용된다.
반면 복제 생성자를 파생 클래스에 명시적으로 정의할 때는 아래 예제처럼 반드시 부모의 복제 생성자를 호출해주어야 한다. 만약 부모의 복제 생성자를 호출하지 않으면 부모클래스의 데이터에 대해서는 디폴트 생성자가 사용된다.
class Super
{
public:
Super();
Super(const Super& inSuper);
};
class Sub : public Super
{
public:
Sub();
Sub(const Sub& inSub);
};
Sub::Sub(const Sub& inSub) : Super(inSub)
{
}
마찬가지로 대입 연산자 operator=에 대해서도 거의 항상 부모버전의 operator=을 호출해주어야 한다. 부모 버전의 operator= 호출을 생략하는 경우는 아주 특이한 상황에서 객체 일부만 대입되길 원할 때 뿐이다. 다음 코드는 파생 클래스의 operator=에서 부모의 operator=를 호출하는 예 이다.
Sub& Sub::operator=(const SUb& inSub)
{
if(&inSub == this) {
return *this;
}
Super::operator=(inSub) // 부모의 operator=을 호출
// 파생 클래스의 멤버 대입 수행(코드 생략)
return *this
}
파생 클래스에서 복제 생성자나 대입 연산자를 명시적으로 정의하지 않더라도 부모 클래스가 작동하는 데는 문제가 없다. 하지만 파생 클래스에서 명시적으로 복제 생성자나 대입 연산자를 정의할 때는 반드시 부모 버전의 복제 생성자나 대입 연산자를 호출해주어야 한다.
9.6.5 virtual 심화탐구
virtual메서드만 올바르게 오버라이딩 될 수 있다고 표현했었는데, 올바르게 라는 표현을 사용한 이유는 virtual이 아니더라도 오버라이딩 할 수 있기 때문이다. 하지만 virtual이 아닌 메서드를 오버라이딩하면 의도와 달리 미묘하게 동작하는 문제가 발생한다.
9.6.5.1 오버라이딩 대신 숨기기
다음 코드는 메서드 하나가 가진 베이스 클래스와 파생 클래스를 보여주고 있다. 파생 클래스에서는 virtual이 아닌 베이스 클래스의 메서드를 오버라이딩하고 있다.
class Super
{
public:
void go() { cout << "go() called on Super" << endl; }
};
class Sub : public Super
{
public:
void go() { cout << "go() called on Sub" << endl; }
};
Sub 객체에서 go()를 호출해보면 의도대로 작동하는 듯 하다.
Sub mySub;
mySub.go();
위 코드의 실행 결과는 예상대로 'go() called on Sub'다. 하지만 메서드가 virtual이 아니므로 실제로는 오버라이딩된 것이 아니다. 단지 Sub클래스에서 Super의 go()와는 완전 별개인 새로운 메서드 go()를 정의했을 뿐이다. 실제로 그런지 보기 위해 다음과 같이 Sub객체를 Super타입 포인터 참조로 접근해보자.
Sub mySub;
Super& ref = mySub;
ref.go();
위 코드의 실행 결과로 'go() called on Sub'를 기대했지만 실제로는 'go() called onSuper'가 출력된다. 변수 ref는 Super의 참조형이고 Super의 go() 메서드는 virtual이 아니기 때문이다. go()를 호출하면 그냥 Super의 go()가 실행된다. go()메서드는 virtual이 아니기 때문에 파생 클래스에서의 오버라이딩 여부를 따지지 않는다.
virtual이 아닌 메서드를 오버라이딩하면 베이스 클래스의 메서드가 숨겨지고 파생 클래스의 메서드가 실행되지만. 이는 파생 클래스 타입으로 접근할 떄만 유효하다.
9.6.5.2 virtual의 내부 구현
메서드 숨김이 일어나는 이유를 알려면 virtual키워드가 어떻게 구현되는지 알아야 한다. 컴파일러가 클래스 정의 코드를 컴파일하면 그 클래스의 모든 데이터 멤버와 메서드가 들어있는 바이너리 객체가 만들어진다. virtual이 아닌 메서드의 경우 메서드 호출 시 제어권의 전달이 컴파일 타임에 맞추어서 직접 하드코딩된다.
하지만 virtual로 선언된 메서드의 경우 vtable(virtual table)이라고 부르는 특별한 메모리 영역을 찾아보게 된다. 하나 이상의 virtual메서드를 가진 클래스는 각각 자신만의 vtable을 통해 virtual메서드의 구현부를 가리키는 포인터를 관리한다.
어떤 객체의 메서드가 호출되면 그 객체에 딸린 vtable에서 해당 메서드의 오버라이딩된 포인터를 찾아서 객체의 실제타입에 맞추어 올바른 버전의 메서드가 실행되도록 한다.
vtable이 메서드 오버라이딩을 어떻게 지원하는지 이해하기 위해 다음의 Super와 Sub클래스를 살펴보자.
class Super
{
public:
virtual void func1() {}
virtual void func2() {}
void nonVirtualFunc() {}
};
class Sub : pulbic Super
{
public:
virtual void func2() override {}
void nonVirtualFunc() {}
};
다음처럼 두 개의 인스턴스를 만들었다고 가정하자.
Supoer mySuper;
Sub mySub;
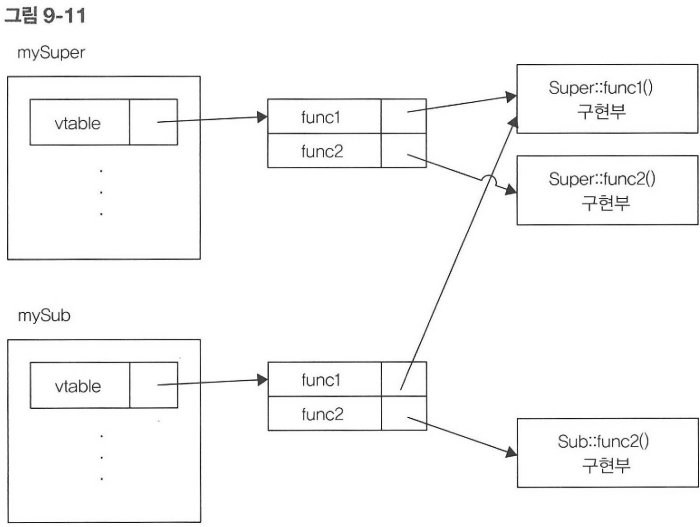
위 그림은 상위 수준에서 본 각 인스턴스와 vtable의 관계도 다. mySuper객체는 자신만의 vtable에 대한 포인터를 가지고 있다. 이 vtable은 두 개의 항목 func1()과 func2()를 담고 있다. 이들은 각각 Super::func1()과 Super::func2()의 구현부가 있는 메모리를 가리킨다.
mySub도 자신만의 vtable을 가지고 있고 두 개의 항목 func1()과 func2()를 담고 있다. func1()항목은 오버라이딩되지 않았기 때문에 Super::func1()을 가리킨다. 반면에 func2()항목은 오버라이딩되었기 때문에 Sub::func2()를 가리킨다.
여기서 nonVirtualFunc()메서드는 버추얼 메서드가 아니기 때문에 vtalbe에 기술되지 않음을 주의해서 보자.
9.6.5.3 virtual 키워드에 대한 논쟁
앞서 언급했듯 모든 메서드를 virtual로 선언하는것을 권고하고 있다. 그렇다면 애당초 virtual키워드는 왜 만들어진 것일까? 그냥 컴파일러가 모든 메서드를 virtual로 취급하면 되지 않나? 실제로 그렇게 할 수도 있다. 많은 프로그래머가 모든 것을 virtual로 해야 한다고 생각한다. java언어는 모든 메서드를 무조건 virtual로 취급하고 있다.
이러한 논란에도 virtual키워드가 존재하는 이유는 vtable의 이용에 따른 오버헤드 때문이다. virtual메서드를 호출하기 위해서는 포인터를 역참조하여 실행할 메서드의 위치를 찾아오는 부가적인 작업을 해야한다. 대부분 이러한 오버헤드는 무시할 수 있을 만큼 작지만 C++언어를 디자인한 사람들은, 최소한 그 당시에는, 선택권을 주는 것이 더 낫다고 판단했다.
만약 오버라이딩 자체가 필요하지 않다면 virtual을 사용할 필요가 없고 그에 따라 vtable활용에 따른 오버헤드도 없어지게 된다. 하지만 요즘 사용되는 CPU의 성능에서는 virtual호출의 오버헤드가 나노초 이하의 작은 단위로 측정되고 있고 기술 발전에 따라 이 숫자는 더 작아질 것이 분명하다.
대부분의 어플리케이션에서는 virtual메서드와 일반 메서드의 성능 차이를 측정하기 어렵다. 따라서 소멸자를 포함하여 모든 메서드를 virtual로 선언하라는 권고는 여전히 바람직하다.
virtual메서드는 성능 외에도 코드 크기에도 영향을 미친다. 메서드 구현부와 별도로 각 객체에 메서드 포인터를 저장할 공간이 추가로 필요하다. 하지만 전체적으로 봤을 때는 매우 작은 차이다.
9.6.5.4 virtual 소멸자의 필요성
모든 메서드를 virtual로 선언하는데 반대하는 프로그래머라도 소멸자 만큼은 virtual로 선언해야 한다는 데 동의한다. 왜냐하면 소멸자가 virtual이 아닌 경우 객체가 소멸하더라도 해제되지 않은 메모리 영역이 남겨질 수 있기 때문이다. 소멸자가 버추얼로 선언되지 않는 경우는 해당 클래스가 final로 선언되는 경우 하나 밖에 없다.
예를 들어 어떤 파생 클래스가 생성자에서 메모리를 동적으로 할당받은 다음 소멸자에서 해제한다고 하자. 이 경우 소멸자가 호출되지 않는 한 해당 메모리는 절대 해제될 수 없다. 그런데 다음 예제에서 보여주는 것 처럼 컴파일러가 virtual이 아닌 소멸자 호출을 건너뛰게 하는 것은 아주 쉽다.
class Super
{
public:
Super();
~Super();
};
class Sub : public Super
{
public:
Sub() { myString = new char[30]; }
~Sub() { delete [] mString; }
private:
char* mString;
};
int main()
{
Super* ptr = new Sub(); // mString은 잇 ㅣ점에 할당된다.
delete ptr; // ~Super가 호출되었지만 소멸자가 virtual이 아니기 때문에
// ~Sub은 호출되지 않는다~
return 0;
}
그럴 수 밖에 없는 특별한 이유가 있거나, 클래스가 final로 지정되어 있는 경우가 아니라면 소멸자를 포함 한 모든 메서드를 virtual로 선언하는 것이 바람직하다. 단, 생성자는 예외다. 생성자는 virtual로 선언할 수 없고 그럴 필요도 없다. 객체를 생성할 떄는 항상 특정 타입을 지정하기 때문이다.
9.6.6 런타임 타입 정보
다른 객체지향 언어와 달리 C++는 런타임이 아닌 컴파일 타임에 많은 것이 결정된다. 오버라이딩의 경우 앞서 배운 것처럼 메서드를 간접적으로 호출하기 때문에 작동하는 것이지 객체 스스로 자신이 속한 클래스가 무엇인지 알고서 대응하는 것은 아니다.
하지만 C++에도 객체의 런타임 정보를 얻을 수 있는 기능이 있다. 이런 기능은 보통 런타임 타입 정보(Runtime Type Imformation[RTTI])라는 이름으로 한데 모여있다. RTTI는 객체가 속한 클래스와 연동되는 여러 가지 기능을 제공한다.
그중 한가지가 dynamic_cast다. dynamic_cast는 RTTI를 이용하여 객체 계층 간에 타입 변환을 안전하게 할 수 있도록 해준다.
RTTI의 또 다른 기능으로 typeid연산자가 있다. typeid연산자는 런타임에 객체의 타입이 무엇인지 알 수 있게 해준다. 대부분은 virtual메서드를 이용해서 객체 타입에 따른 작업 처리가 가능하기 때문에 typeid에 의존해야 할 상황은 많지 않다.
다음은 typeid를 이용하여 객체 타입에 따라 서로 다른 메시지를 출력하는 예 이다.
#include <typeinfo>
void speak(const Animal& inAnimal)
{
if(typeid(inAnimal) == typeid(Dog&|)) {
cout << "Woof!" << endl;
} else if(typeid(inAnimal) == typeid(Bird&)) {
cout << "Chirp!" << endl;
}
}
이런 형태의 코드를 발견하면 virtual메서드를 이용하도록 다시 구현하는것이 바람직하다고 생각할 것이다. 이 예에서는 Animal클래스의 speak()메서드를 virtual로 선언ㅁ하고 Dog와 Bird클래스에서 speak()를 오버라이딩해서 각각 'Woof!'와 'Chirp!'를 출력하게 한다. 이렇게 기능이 객체에 연관되도록 하는 것이 객체지향 프로그래밍 방식에 더 부합한다.
객체가 다형성을 가지면 virtual메서드가 하나라도 있어야 typeid연산자가 올바르게 작동한다. 버추얼 메서드가 하나도 없는 클래스에 dynamic_cast를 하면 컴파일 오류가 발생한다.
typeid연산자의 주요 활용처중 하나는 로깅과 디버깅을 할 떄다. 다음 코드는 typeid를 로깅에 이용하고 있다.
logObject()함수는 Loggable객체를 파라미터로 받는다. 이는 믹스인 클래스 패턴의 활용 예로, 어떤 객체든 Loggalbe 클래스를 부모로 두고 getLogMessage()메서드를 정의하고 있기만 하면 로그를 남길 수 있다.
#include <typeinfo>
void logObject(const Loggable& inLoggableObject)
{
logfile << typeid(inLoggableObject).name() << " ";
logfile << inLoggableObject.getLogMessage() << endl;
}
logObject()함수는 객체의 클래스 이름과 로그 메시지를 파일에 남긴다. 이런 방식으로 저장되면 나중에 로그 파일을 볼 때 각 로그가 어느 객체에 의해 생성되었는지 찾아볼 수 있다.
typeid를 로깅이나 디버깅 용도 외에 다른 목적으로 사용할 때는 typeid대신 virtual메서드로 재구현할 수 없는지 생각해본다.
9.6.7 public이 아닌 상속
지금까지 예제에서는 클래스를 상속받을 때 모두 public키워드를 사용했다. 그렇다면, private나 protected는 사용할 수 없나? 이에대한 답은 할 수 있다 이고, 실제로도 흔하게 사용된다.
부모와의 관계를 protected로 선언하면 베이스 클래스의 모든 public메서드가 파생클래스에서 protected로 취급된다.
이와 비슷하게 private로 선언하면 베이스 클래스의 모든 public, protected메서드와 멤버가 파생 클래스에서 private로 취급된다.'
이렇게 부모 클래스에 대한 접근 권한을 일괄적으로 바꿔야할 상황은 별로 많지 않다. 오히려 애당조 디자인이 잘못되었다는 것을 암시하는 경우가 많다. 어떤 프로그래머는 클래스의 컴포넌트를 만들기 위해 이러한 기능을 남용하기도 한다. 이럴 때는 보통 다중 상속을 곁들일 떄가 많다.
예를 들어 Airplane클래스를 만들면서 엔진과 동체를 데이터 멤버로 내장하는 대신 엔진 클래스와 동체 클래스를 protected로 상속받는다. 이렇게 함으로써 밖에서 볼 떄는 엔진과 동체가 보이지 않지만 Airplane클래스 안에서는 이용할 수 있다.
non-public상속이 필요한 경우는 매우 드물다! 사용해야 한다면 주의하는것 이 좋다. 대부분의 프로그래머는 non-public상속에 익숙치 않다.
9.6.8 버추얼 베이스 클래스
앞서 다중상속의 예에서 아음 그림과 같은 부모를 가지는 서로 다른 두 클래스를 베이스 클래스로 상속받게 될 때 어느 쪽 부모 클래스를 사용해야 할지 모호해지는 경우를 살펴보았다. 이 문제에 대한 해결책으로 중복되는 부모 클래스가 메서드를 가지지 않도록 하여 모호한 메서드 호출이 발생할 여지를 없앨것을 제안했었다.
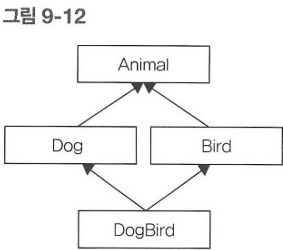
그런데 C++는 이런 상황에서도 중복되는 부모 클래스가 메서드를 가질 방법을 제공해준다. 중복되는 부모 클래스를 버추얼 베이스 클래스(virtual base class)로 상속받으면 모호성이 발생하지 않는다.
다음 코드는 중복되는 베이스 클래스 Animal에 sleep()메서드를 추가하였지만, Dog과 Bird클래스에서 Animal클래스를 버추얼 베이스 클래스로 상속받기 때문에 모호성 문제가 발생하지 않는다. 만약 Animal을 상속받을 때 virtual키워드를 사용하지 않는다면 DogBird객체에서 sleep()메서드를 호출할 떄 두 경로로 상속받은 Animal클래스 객체 중 어느 쪽 경로의 Animal객체에서 Sleep()메서드를 호출해야 할지 모호해져서 컴파일 에러가 발생한다.
하지만, Animal을 virtual로 상속받은 경우 공통 부모에 대해서는 하나의 객체만 생성되기 때문에 sleep()이 실행될 때 어느쪽 객체를 이용해야 할지 선택할 필요가 사라진다.
class Animal
{
public:
virtual void seat() = 0;
virtual void sleep() { cout << "zzzzz..." << endl; }
};
class Dog : public virtual Animal
{
public:
virtual void Bark() { cout << "Woof!" << endl; }
virtual void eat() override { cout << "The dog has eatnen." << endl; }
};
class Bird : public virtual Animal
{
public:
virtual void chirp() { cout << "Chirp!" << endl; }
virtual void eat() override { cout << "The bird has eaten." << endl; }
};
class DOgBird : public Dog, public Bird
{
public:
virtual void eat() override { Dog::eat(); }
};
int main()
{
DogBird myConfusedAnimal;
myConfusedAnimal.sleep(); // Animal이 virtual이기 때문에 모호성이 발생하지 않는다.
return 0;
}
버추얼 베이스 클래스는 클래스 계층의 모호성을 피할 수 있게 해주는 좋은 방법이다. 유일한 단점은 많은 C++프로그래머가 버추얼 베이스 클래스를 잘 모른다는 것이다.
'전문가를 위한 C++정리' 카테고리의 다른 글
| 10. C++의 까다롭고 유별난 부분들 10.2 키워드 혼동 (0) | 2024.03.07 |
|---|---|
| 10. C++의 까다롭고 유별난 부분들 10.1 참조형 (0) | 2024.03.05 |
| 9. 클래스 상속 활용 테크닉 9.5 다중 상속 (0) | 2024.02.29 |
| 9. 클래스 상속 활용 테크닉 9.4 다형성을 위한 상속 (0) | 2024.02.27 |
| 9. 클래스 상속 활용 테크닉 9.3 부모를 존중하라 (0) | 2024.02.22 |